



























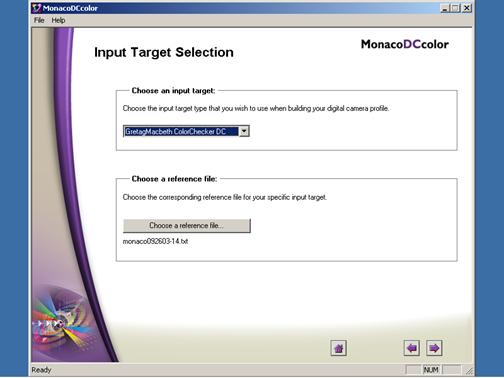
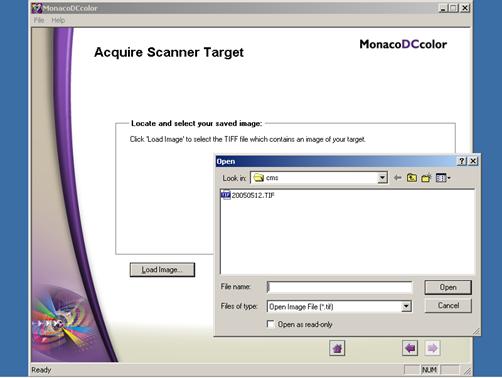
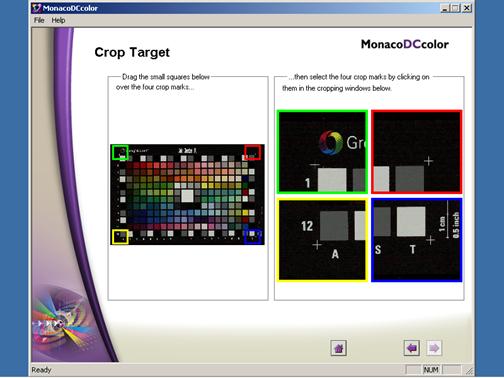
期刊報紙數位化工作流程指南
Tags: 指南 發表: 2009-10-07, 點閱: 60,277 , 加入收藏櫃 , 列印
,
列印
,  轉寄
轉寄
想加入的書籤:














參與研發單位:國家圖書館
提供單位:國家圖書館
使用單位:國家圖書館
國家圖書館閱覽組(期刊)93 年4 月第13 次修訂
1. 期刊批次掃描以掃描全本期刊為原則。即時期刊影像掃描則以單篇為掃描單位,但皆適用本編碼原則。本掃描之期刊影像需與本館相關資料庫系統自動產生關連,以利影像調閱及文獻傳遞,故編碼過程需配合本館「中華民國出版期刊指南系統」、「中華民國期刊論文索引影像系統」、及「國家圖書館新到期刊目次服務系統」等書目資料的著錄原則。資料庫網址:http://readopac.ncl.edu.tw/
2. 每本期刊其檔案目錄分為三層:期刊識別號、卷期總號、出版年月。再以頁碼區分檔名,檔名中英文字母皆為小寫。
例: 研考月刊第1 卷1 期民國85 年1 月第1 頁→00000001/1n1/8501/00000001.tif
說明:
2.1 第一層:期刊識別號
共 8 bytes,由中華民國期刊指南系統查出期刊識別號。
例: 研考雙月刊 → 00000001
2.2 第二層:卷期總號
由期刊之封面與書名頁查出該期之卷期總號時參考本館「中華民國期刊論文索引影像系統」及「國家圖書館期刊目次系統」之卷期著錄方式。
卷期總號長度不受限於8bytes,應完整編碼。
2.2.1 凡卷期總號中含有特殊符號或文字者,請以下列英文字母代替之。
卷 : → n 例: 3 卷1 期 3:1 →3n1
合刊 / → x 例: 4、5 期合刊 4/5 →4×5
合刊 - → - 例: 62 卷1-2 期 62:1-2 →62n1-2
總號 = → e 例: 3 卷1 期總號495
3:1=495 →3n1e495
試刊號, 試刊 →t
創刊號 → f
第十章 典藏品識別碼暨數位檔案命名規範
1.10.2.2
特刊 → s 例: 特刊16 → s16 5(特刊) → 5s
復刊 → r 《 r 之後請勿加_ 》 例: 復刊16 →r16
增刊 → a
專刊 → b
革新 → j
索引 → i 例: 1-12 期索引 → i1-12
上 → u 例: 70 期上 70(上) → 70u 去除括號()
中 → m 例: 70 期中 70(中) → 70m 去除括號()
下 → d 例: 70 期下 70(下) → 70d 去除括號()
外編、別冊 → c 例: 別冊1 →c1
外編第四種上冊 →c4u
副刊、附冊、附輯 → g
補編 → h
總目錄 → o(英文)
新,新刊 →y 例: 新3:2 →y3n2
凡無卷期者,請輸入0(數字)
春 → sp 例: 1994 春季號 1994:春 → 1994nsp
夏 → su 例: 87 夏季號 87:夏 → 87nsu
秋 → au 例: 84 秋季號 84:夏 → 84nau
冬 → wi 例: 84 冬季號 84:冬 → 87nwi
2.2.2 凡卷期外有標示學科分冊者代碼如下:
特 刊 → s
例 第5 期特刊 5(特刊) → 5s
人文分冊 →hu
例: 1 卷1 期人文分冊 1:1(人文分冊) →1n1hu
人文社會篇 →hs
科技人文篇 →sh
社會科學分冊 →so
例: 1 卷1 期社會科學分冊
1:1(社會科學分冊) →1n1so
管理科學分冊 → ma
例: 1 卷1 期管理科學分冊
10-2 期刊影像掃描檔案編碼原則(原10-2 更新)
1.10.2.3
1:1(管理科學分冊) →1n1ma
文學院 →li
例: 35 期文學院 35(文學院) →35li
理學院 →sc
例: 35 期理學院 35(理學院) →35sc
工學院 →te
例: 35 期工學院 35(工學院) →35te
管理學院 →ma
例: 35 期管理學院 35(管理學院) →35ma
社會科學學院 →so
例: 35 期社會科學學院 35(社會科學學院) →35so
農學院 →ag
例: 35 期農學院 35(農學院) →35ag
文學部門 →li
例: 14 期文學部門 14(文學部門) →14li
商學部門、商學‧管理部門 →bi
例: 14 期商學部門 14(商學部門) →14bi
理工部門 →sc
例: 14 期理工部門 14(理工部門) →14sc
區域研究部門 →ar
例: 13 期區域研究部門 13(區域研究部門) →13ar
文商理工部門→lb
例: 16 期文商理工部門 18(文商理工部門) →16lb
文學與商學部門 →li
例: 12 期文學與商學部門
12(文學與商學部門) →12li
社會科學學院 →so
例: 35 期社會科學學院 35(社會科學學院) →35so
科技‧醫學篇 →st
例: 32 期科技‧醫學篇 32(科技‧醫學篇) →32st
文史‧社會篇→ lh
例: 32 期文史‧社會篇 32(文史‧社會篇) →32lh
第十章 典藏品識別碼暨數位檔案命名規範
1.10.2.4
軍事社會特刊→ mi
中國系列 → ch
行政革新專號→ ad
2.2.3 凡無卷期編號者, 掃描時編碼為0
2.3 第三層:出版日期
由期刊之封面與書名頁查出該期之出版日期,同時參考本館「中華民國期刊論文索引影像系統」、「國家圖書館期刊目次系統」之日期著錄方式,以求一致性。出版日期長度不限於8bytes,以詳盡著錄為原則,如年月日。但須配合以上系統之著錄方式。出版日期採民國紀元。
2.3.1 凡出版年月日中含有“民”字者,請省略不予註記。
例: 民87 年1 月 →8701
2.3.2 年月日間之“‧”號逕行省略,不輸入亦不空格
例: 87.01 →8701
2.3.3 下列文字請以英文字母代替之:
春 → sp 秋 → au
夏 → su 冬 → wi
例: 民87.春 →87sp
2.3.4 合刊的年月處理如下
23-24 民76.11-12 → 23-24 76.11-12
民75.12-76.01 → 7512-7601
3. 頁碼(檔名)編碼
頁碼檔名長度一般以8bytes 為原則,少數特例可長達9bytes。
例如:第100 頁 → 00000100.tif
第100 頁後之插頁→000100_1.tif
以內文頁碼加上“.tif”作為檔名。如內文第 1 頁,其檔名為
“00000001.tif”。
注意事項:
3.1 內文第 1 頁前面之各頁(即非正文部份),如封面、目次、封底等,請自封面起依序計數,頁碼第一位加“ a”以區別之,如: a0000001.tif ,a0000002.tif…
3.2 內文後面多出且原本未編頁碼之各頁,請依原文最後之頁碼繼續編號下去即可。
3.3 原文編有頁碼或實際有佔頁碼但未編頁碼之空白頁或廣告頁等請仍依原順序掃入。
3.4 原文未編頁碼且為多餘之空白頁請予跳過不掃。
3.5 內文中之插頁,如原文未編頁碼,則於接續之前頁後加“_”連續編碼。如:
在86 頁至87 頁間插頁 2 頁但未編碼,請以“000086_1.tif”、“000086_2.tif”編號。
3.6 期刊分左、右版次者,以右版為主為原則,但仍需先查核期刊索引及期刊目次系統之編碼,以配合之。左版頁碼需以L(小寫)區別,右版頁須以R(小寫)區別。
如:頁左33-左40“,檔名為“L0000033.tif”~L0000040.tif
如:頁右12-右20“,檔名為“R0000012.tif”~R0000020.tif
注意:一本期刊不須同時區分左、右版,應取其一為主,另一版加註區別即可,原則上以加註左版者居多。但須配合國圖期刊索引與目次系統之著錄方式。
3.7 凡標明“頁中”或“中”者請轉換為“m”。如“頁中13-14”,輸入檔名為“m0000013.tif”~“m0000014.tif”
3.8 凡正文中每篇文章皆以”1”起頁者,依篇序頁碼前分別以 ()冠各篇序號,頁碼轉換時規則如下:
□□ □□ □□□□. tif
附錄 篇 頁 碼
例: 第一篇1-17 頁
(1)1-(1)17 →00010001.tif-00010017.tif
第二篇1-18 頁
(2)1-(2)18 →00020001.tif-00020018.tif
第21 篇1-18 頁
(21)1-(21)18 →00210001.tif-00210018.tif
頁(A)27-(A)33 → 00010027.tif-00010033.tif
頁(y)1-(y)5 → 00250001.tif~00250005.tif
附錄(a)7~附錄(a)10
→ap010007.tif-ap010010.tif
*附錄 → ap
*a、b、c……依英文順序轉換例a=01 b=02 ……z=26
第十章 典藏品識別碼暨數位檔案命名規範
1.10.2.6
3.8.1 前述情形若又有左右起頁之橫直版之不同,則須多加一碼,冠以L 或R 分別區分左起頁版或右起頁版,此種編碼會有9 位。頁碼轉換時規則如下:
R□□□□□□□□. tif
L□□□□ □□□□. tif
例: 左起頁 第一篇1-17 頁
L (1)1-(1)17 →L00010001.tif-L00010017.tif
右起頁 第二篇1-18 頁
R(2)1-(2)18 →R00020001.tif-R00020018.tif
3.9 凡正文有兩組頁碼標示者,一組各篇從1 編頁,一組為總頁碼者,依總頁碼編。但若有兩組總頁碼,一組自1 編,一組是接前期續編者(頁數號碼較大),則依第一頁起始者編,但仍應先查核本館期刊索引及期刊目次系統之著錄方式,或請示館方負責人員。
3.10 凡頁碼編排有疑義應先參考期刊索引系統或期刊目次系統登錄方式,如仍有問題應先請示館方負責人員。
參與研發單位:國家圖書館
提供單位:國家圖書館
使用單位:國家圖書館
國家圖書館閱覽組(期刊)民國90 年1 月第二次修訂
1. 本報紙編碼原則適用於紙本報紙掃描為影像檔,及微縮捲片(35mm)報紙轉製影像檔之檔案編碼處理。
2. 紙本報紙影像掃描以每日為單位。
3. 其影像檔案目錄分為二層:報紙識別號、出版日期。再以版次區分檔名,檔名中英文字母皆為小寫。
例:臺灣新生報 民國50 年1 月1 日 第1 版
→ /68600106/19610101/00000001.tif
3.1 報紙識別號
檔名長度為 8 bytes,由本館中華民國期刊指南系統查出報紙識別號。
例:臺灣新生報
識別號 → 68600106
3.2 出版日期
不限檔名長度,原則上以完整著錄為原則,並將出版日期轉換為西元紀元。
例:民國50 年1 月1 日 → 19610101
3.3 版次
檔名長度共8bytes,以一版面單位為一頁。
例:第一版 → 00000001.tif
非定期專刊、增刊、特刊 例: 專刊4 版 → s0000004.tif
單獨編頁碼之廣告 → ad 例:廣告第8 版→ ad000008.tif
3.4 編碼實例:
民生報
現代生活:a0000003.tif
體育戶外:b0000005.tif
影視娛樂:c0000006.tif
第十章 典藏品識別碼暨數位檔案命名規範
1.10.6.2
影視快訊:cs000007.tif
家庭消費:d0000008.tif
旅遊專刊:e0000009.tif
行程專輯:f0000010.tif
大成報
體育報:b0000002.tif
影劇報:c0000003.tif
經濟日報
金銀島:sb000003.tif
科技島:ss000005.tif
其他專刊:s0000003.tif
同一天第二種專刊 s1000004.tif
同一天第三種專刊 s2000003.tif
China Post
增刊:s0000004.tif
檔案格式 |
建議規格 |
說明 |
||
|
文字檔 |
||||
|
資料永久保存格式 |
檔案格式: TIFF |
將資料數位化典藏,保持原有風貌。提供使用者作重製、壓縮處理或其他圖像處理交換之用。 |
||
|
網路下載格式 |
檔案格式:JBIG or JBIG2 |
提供使用者網路上觀看及列印用。 |
||
|
預覽影像 |
檔案格式:GIF |
提供使用者預覽及選擇欄位用。 |
||
|
影像檔 |
||||
|
資料永久保存格式 |
檔案格式:TIFF |
將資料數位化典藏,保持原有風貌。提供使用者作為重製、壓縮處理或其他圖像處理交換之用。 |
||
|
資料服務/參考格式 |
檔案格式: JFIF(JPEG交換格式) |
提供使用者網路上觀看及列印用。 |
||
|
縮圖影像 |
檔案格式:GIF |
提供使用者預覽及選擇欄位用。 |
||
.jpg)
資料來源:大葉大學資訊管理系 曾逸鴻助理教授
《光學文字辨識(OCR)技術整理報告》
當字元切割完成,即可將每個字元影像丟入辨識引擎做辨認。最基本的辨認方式,即是將字元影像做大小的正規化(Normalization),然後與資料庫中每個中文字的影像(亦已經過正規化)做模版比對(Template matching),計算相對位置的顏色是否相同,找出差異最小者即為辨識結果。此種模版比對方式為確實掌握文字特性,且所需的記憶體空間較大,比對速度也慢,所以並不被大多數OCR系統所採用。在辨識引擎的內部技術,我們可分特徵抽取、特徵比對與加速技術三部分來描述。
1. 特徵抽取
特徵抽取是辨識引擎最重要的一節,要找到最少的特徵,來得到最佳的辨識效果,常採用的特徵可分為結構特徵與統計特徵,結構特徵包括文字影像內的線段(line segment)、筆畫(stroke)、曲線(curve)、環路(loop)等,通常文字影像需先經過細線化(thinning),將字元轉成只剩一個像素的寬度,再來抽取結構特徵。經過實驗,利用結構特徵所建構的OCR辨識引擎,較適合辨認印刷清楚且筆畫較少的字元,不太適合於建構商用OCR軟體。統計特徵則將文件影像的像素分佈作分析,利用大量的學習影像來計算特徵向量的平均值與變異度。只要學習影像收集的夠完整、數量夠多,利用統計方式建構出的OCR辨識引擎較能做較廣泛的應用。常採用的統計特徵如下:
(1) 筆畫數目(Stroke count)特徵:對於某個參考點(reference point),往上下左右延伸,計數可通過多少筆畫。此處筆畫的定義為,延伸線上的點「由白變黑」再「由黑變白」,算是一個筆畫。因此對於每個參考點,我們可得到四個特徵值。
(2) 邊緣像素數目(Contour pixel count)特徵:由於不同文件切出的字元影像擁有不同的筆畫寬度,此特徵乃計數字元的邊緣點數目。
(3) 邊緣方向數目(Contour directional count)特徵:考慮邊緣像素,計算四個方向(水平、垂直、左撇、右捺)的邊緣點數目,可得到四個特徵值。
(4) 網眼特徵(Cellular feature):對於某個參考點,往上下左右延伸,計算要延伸多長的距離始可碰到第一個黑點,可得到四個特徵值。
(5) 周圍背景面積 (Peripheral background area, PBA)特徵:由字元邊界往內走,走到第一個黑點便停止,記錄其距離,將所有距離累計,即為此特徵值。由於此種特徵不管字元中心部分,只描述其周圍的白色背景面積,適於辨認因墨水過多導致中心部分容易糊成一坨的字元。
(6) 周圍背景差異 (Peripheral background difference, PBD)特徵:與PBA類似的計算法,只是此特徵記錄的事兩距離的差異,而不是累計距離。因此,可分辨雖然累積距離相同,但距離先長後短與先短後長的不同。一樣適於辨認中心部分易模糊的字元。
(7) 橫越個數特徵 (Crossing counts feature):由字元左邊界往右邊界走,計算通過的筆畫數,加以累計,垂直方向亦同。
(8) 投影特徵 (Projection feature):將字元影像分別往四個方向(水平、垂直、左撇、右捺)投影,設適當的門檻值,分別在此四個投影圖中,計算投影量高於門檻值的筆畫的個數,當作特徵值。
另外,由於要找到效果很好的特徵不易,一旦找到適當的特徵,為求更精準描述字元,通常會將字元做切塊,例如邊緣方向數目特徵雖然只有四個特徵值,若先將字元切成8×8塊,在每一塊抽出四個特徵值,則此字元總共可得到8×8x4=256個特徵值。字元的切塊方式有兩種:
(1) 等分(uniform)切割:直接以字元的寬或高等距切成數等分。
(2) 不等分(non-uniform)切割:先將所有黑點往X軸投影,將投影圖切成數份,使得每一份內的的黑點數目相同,在對Y軸投影,以同樣方式切成數份。此方式切出的區塊大小不同,但較可容許手寫字的變異度,及印刷字的雜訊。
2. 特徵比對
特徵抽取完,成為一個多維的特徵向量(Feature vector)![]() 後,就要與資料庫中經過學習各字(中文字常用字數為5401字)的代表特徵向量
後,就要與資料庫中經過學習各字(中文字常用字數為5401字)的代表特徵向量![]() 作比對。由於學習與辨識所採用抽取特徵的過程都一樣,因此,比對方式為兩特徵向量間,計算相對維度特徵值的差異和。
作比對。由於學習與辨識所採用抽取特徵的過程都一樣,因此,比對方式為兩特徵向量間,計算相對維度特徵值的差異和。
假設特徵向量共256維,未知字元影像抽出的特徵向量為![]() ,字元j的代表特徵向量為
,字元j的代表特徵向量為![]() ,其標準差(standard deviation)為
,其標準差(standard deviation)為![]() ,計算兩特徵向量差異值
,計算兩特徵向量差異值![]() 的方法有下列幾種:
的方法有下列幾種:
(1) Minimum distance: ![]()
(2) Euclidean distance: 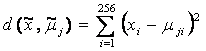
(3) Cross correlation distance: 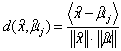
(4) Modified Mahalanobis distance: 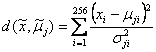
(5) Li and Yu distance: 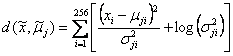
3. 加速技術
由於中文字數量極多,辨識特徵取出的維度亦不少,使得如何加速比對過程,也成為相當重要的研究課題,常採用的方法有下列幾種:
(1) 分群法(Clustering):先以簡單特徵將中文字分成數群,不同群內字元可重複或不重複。未知影像抽完簡單特徵後,先決定此未知影像會落於哪一群,再以較複雜的特徵,與該群內的字元做細部比對。此方式需先決定哪些字元屬於同一群,且不同未知影像只要落於同一群,其細部比對的候選字元均相同。
(2) 候選字選擇法(Candidate selection):此法不必事先決定哪些字元屬於同一群。未知影像抽完簡單特徵,就與所有字元做比對,取前幾名(如前百分之一)再以複雜特徵做細部比對。因此,不同未知影像其細部比對的候選字元必定不同。
(3) 分支界定法(Branch and Bound):前兩種加速法均致力於降低比對的字元數目,因此會降低整體辨識率,此法則設法加速特徵向量的比對速度,主要用於複雜特徵的細部比對過程。首先,先按照重要性將特徵向量的各維特徵值做重排列,以最重要的幾個特徵值與代表特徵向量作距離的計算,按照此累計距離將候選字元的比對順序重排。在來求出未知字元與第一個候選字元的完整距離,以此為一門檻值,在計算第二個候選字元以後的完整辨識距離的過程中,每累計一個維度特徵值的差異時,便與此門檻值做比較,若超過門檻值,則未計算的維度也不用再計算,便可跳到下個候選字。若累計完所有維度得到完整距離,仍未超過門檻值,則將門檻值改為此完整距離。此加速法的最大優點為完全不會降低整體辨識率。
 期刊報紙數位化工作流程指南全文下載 (11.6 MB, 3,291 hits)
期刊報紙數位化工作流程指南全文下載 (11.6 MB, 3,291 hits)
評分:
 (No Ratings Yet)
(No Ratings Yet)
