Posted By 褚 如君 On 十二月 10, 2007 @ 12:17 pm In 數位化書籍 | No Comments
|
目 錄
[1] 壹、引言
[2] 貳、數位化工作流程圖
|
壹、引言
民國九十一年一月一日,行政院國家科學委員會依據「數位博物館計畫」、「國家典藏數位化計畫」,以及「國際數位圖書館合作計畫」等三個計畫的合作經驗,整合規劃了「數位典藏國家型科技計畫」;計畫的首要目標是將國家重要的文物典藏數位化,建立國家數位典藏。計畫辦公室下設有五分項計畫,分別為:內容發展、技術研發、應用服務、訓練推廣及維運管理分項計畫,協助總計畫相關業務的推動。而其中「內容發展分項計畫」負責數位典藏內容之管理、規劃及各機構間的橫向聯繫、協調等事宜,並將各計畫的典藏品依照其性質分成各種主題小組,至民國九十四年止已成立16個主題小組,包括:動物、植物、地質、人類學、檔案、地圖與遙測影像、金石拓片、善本古籍、考古、器物、書畫、新聞、影音、語言、漢籍全文與建築等主題小組。
為因應「內容發展分項計畫」所規劃之主題分類,新聞主題小組於民國九十一年正式成立,以報紙、期刊、新聞影音為主要數位化典藏內容,典藏品形態包含平面報刊媒體與電視媒體之文字、圖像、照片、影音等各項種類。歷年來參與新聞主題小組進行數位化計畫的機構單位有:本國家型計畫「維運管理分項計畫─出版子計畫」(九十一至九十四年度)、國家圖書館「國家圖書館期刊報紙典藏數位化計畫」(九十一年度迄今)、國立交通大學資訊工程系「電視新聞數位博物館」(九十一年度)、國立交通大學傳播研究所「蘭嶼原住民媒體資料庫建置與數位典藏計畫」(九十四年度)、「世新大學北平世界日報內容數位開發計畫」(九十一至九十四年度)以及淡江大學「台灣棒球運動珍貴新聞檔案數位資料館之建置」(九十三年度迄今)。
以下簡略說明新聞主題小組內各計畫之數位化工作內容:維運管理分項計畫─出版子計畫主要負責《國家數位典藏通訊》發行,並以XML標誌語言加以分析進而建立檢索資料庫;國家圖書館則從事館藏之臺灣地區發行期刊約1,000種,與臺灣地區發行報紙約30種之數位化工作,其主要數位化工作項目為期刊典藏影像數位化、報紙典藏數位化、期刊篇目後設資料分析建檔等;國立交通大學資訊工程系則有「電視新聞數位博物館」網路資料庫,典藏中華電視公司新聞影音資料;國立交通大學傳播研究所的典藏有蘭嶼在地刊物《蘭嶼雙週刊》、數位化幻燈片影像資料及蘭嶼地方廣播節目的聲音內容,並建置多媒體資料庫;世新大學資訊傳播學系則取得北平世界日報之微縮膠卷資料(報紙原件存放於北京圖書館),並陸續全文輸入典藏北平世界日報之新聞內容;淡江大學與聯合報合作進行台灣棒球新聞之數位化,並建置「台灣棒球運動珍貴新聞檔案數位資料館」。
為了解各機構單位典藏品內容以及數位化工作程序,內容發展分項計畫亦針對各主題小組進行數位化工作流程之調查,在九十三年曾經出版新聞主題小組數位化工作流程叢書,透過圖像及文字並陳方式來紀錄各計畫單位的數位化工作流程,以提供給其他數位化機構單位相關之參考經驗;而九十四年則預計將不同主題但為相同數位化物件者,進行跨主題式之全面性整合,「物件」包括平面物件─相片(正片、負片、照片)、文書、檔案、期刊報紙、書畫、拓片等;立體物件─動植物標本、考古遺物、地質標本、器物等,其中並以相同數位化方式(如:掃描、攝影翻拍)進行數位化工作流程參考標準之彙整,以提供一套完善的標準作業流程(Standard Operational Procedure,簡稱SOP)作為數位化參考依據。
「期刊報紙全文輸入工作流程參考標準」的目標對象則針對以期刊、報紙為數位化物件的機構單位或有興趣之個人為主,並以全文輸入視為本文數位化方式之重點來撰寫,調查方式則藉由採訪數位化執行廠商並實際測試操作,針對目前全文輸入的現況與技術進行分析及歸納,讓不同階層的使用者能依據實際情形、人力或時間成本等,選擇適合進行數位化的參考標準,也提供其對數位化工作流程更進一步的認識與瞭解。
本文以目前新聞主題小組下的各機構單位數位化計畫為例作說明:「國家圖書館期刊報紙典藏數位化計畫」主要數位化工作為影像掃描,並針對期刊部份建置單篇篇目後設資料;「世新大學北平世界日報內容數位開發計畫」則將世界日報微缩膠捲以人工輸入方式建立新聞資料;「蘭嶼原住民媒體資料庫建置與數位典藏計畫」數位化內容之一為蘭嶼廣播帶,計畫預計以達悟語及漢語全文輸入方式來記錄廣播節目內容;「台灣棒球運動珍貴新聞檔案數位資料館」計畫則將聯合報棒球新聞進一步做更深入的後設資料分析。內容主要包括有:(一)引言(二)數位化工作流程圖(三)前置作業(四)物件數位化程序(五)後設資料與資料庫建置(六)設備與成本分析(七)效益與侷限(八)結語(九)參考文獻等。
〈[11] 目錄〉
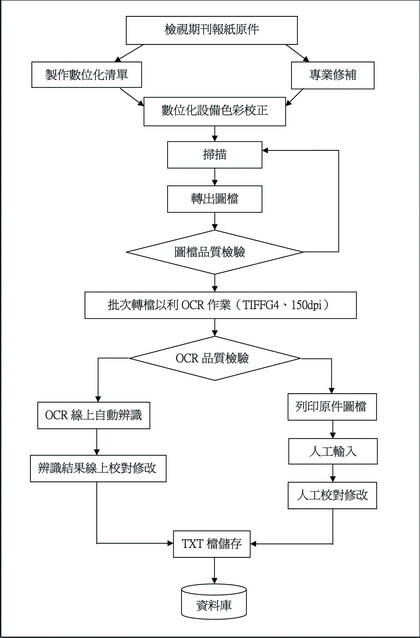
〈[12] 目錄〉
(一)原件檢視與類型
1.技術成熟穩定:微縮技術具百年歷史,且擁有國際統一規格標準。
|
報紙名稱
|
微縮膠卷資料起訖時間
|
數量
|
|---|---|---|
|
聯合報
|
民國40年 ~ 92年12月
|
357卷
|
|
經濟日報
|
民國76年 ~ 92年12月
|
196卷
|
|
民生報
|
民國67年2月 ~ 92年12月
|
234卷
|
|
中華日報
|
民國35年2月 ~ 85年12月
|
269卷
|
這些古老且具有歷史價值的微縮膠卷,經過時間證明其保存時間較為長久,然而隨著資訊科技的發展,微縮膠片技術也迫面臨淘汰的窘境,若沒有延續保留原始寶貴資料的轉換技術,將對資料的可用性造成威脅。
(二)製作清冊
(三)訂定標準規範
1.確立施作方式與工作程序
2.製作文字輸入及校對規範
(四)確立數位化檔案規格及用途
(1)TIFF(Tag Image File Format)
(2)JPEG(Joint Photographic Experts Group)
(3)JPEG2000
(4)PDF(Portable Document Format)
(5)其它格式
|
|
會否失真
|
彩色
|
黑白
|
容量
|
|---|---|---|---|---|
|
TIFF 不壓縮
|
不會
|
可
|
可
|
極大
|
|
TIFF LZW 壓縮
|
不會
|
可
|
可
|
大
|
|
TIFF G4
|
會(部分文字不會)
|
不可
|
可
|
極小
|
|
JPEG 不壓縮
|
會
|
可
|
可
|
大
|
|
JPEG 85% 壓縮
|
會
|
可
|
可
|
中
|
|
JPEG2000
|
不會
|
可
|
可
|
極小
|
|
PDF
|
不確定
|
可
|
可
|
中
|
2. 數位化檔案之用途
(1)印刷
A.期刊報紙之印刷用途
(A)原物重現、再版發行
(B)宣傳展示
(2)實體與數位化保存
(3)網路瀏覽
(4)電子書
以往期刊與報紙的數位化處理方式,有影像掃描、人工輸入、光學文字辨識(Optical Character Recognition,簡稱OCR)、電子報直接轉入資料庫等四種[16] [1],以下將以新聞主題小組內計畫作為範例,各數位化執行單位可依原始資料性質並評估成本預算後,再決定採行的數位化方式,或是數種方式搭配使用。
(一)影像掃描
(二)人工輸入
(三)光學文字辨識
(四)電子報直接轉入資料庫
「辦公室維運分項:出版子計畫」則是直接將電子檔轉入資料庫,以《國家數位典藏通訊》電子報的形式發送,必須另外建置Metadata方能供使用者查詢。又如國內最知名的兩大報系─聯合報以及中國時報,早已將報紙編排方式數位化,並把當日新聞文字稿儲存至資料庫中,而所謂資料庫、Metadata的建置、XML的應用等則自從Internet普及後才逐漸受到重視。
|
數位化方式
|
特點 |
弱點
|
|---|---|---|
|
影像掃描
|
提供原件複本
|
無法全文檢索
|
|
人工打字
|
可直接判斷出缺字或難字
|
耗費大量人力、時間成本
|
|
光學文字辨識
|
速度快、效率高
|
鉛字排版、印刷字與手寫字混排、
注音體、影像檔品質不良等辨識率低
|
|
電子報
|
本身形式即已經過數位化
|
|
一般而言,執行單位在進行文字數位化時,較常遇見情形為OCR辨識率過低,不得已改而採取較耗費成本之人工輸入法,然而,若是能對物件影像檔做些適當的處理以提高其辨識率,不僅能使大量文字圖像內容能夠重新引用並方便檢索,同時也能減少許多不必要的人力或時間成本(OCR辨識處理步驟將於下一章節詳細作說明)。因此,本文除了針對OCR光學文字辨識作一深入探討研究之外,也提供一些選擇人工輸入或OCR辨識的參考依歸,其中以OCR品質檢驗要則為主要考量,利於使用者在進行全文輸入時,依據本身現有的實際情形自行斟酌並作調整。
|
數位化方式
品質檢驗要點
|
OCR光學文字辨識
|
人工輸入
|
|---|---|---|
|
字體
|
常見印刷體
|
純手寫稿、夾雜注音體、數學運算公式
印刷體或手寫字混排、古文或變體字多
|
|
排版格式
|
電腦排版、格式簡單
讀文順序清楚
|
早期鉛字排版、格式複雜、
讀文順序不順暢
|
|
雜點
|
版面較為乾淨、無雜點
|
字體周圍較多標記或雜點
|
|
反差度
|
純黑白稿、字體清晰
、反差度高
|
本身影像品質不佳、字體較為模糊
、反差不明顯
|
就圖檔格式而言,OCR軟體在個人電腦問世後不久即產生,然而當時僅能支援150dpi、黑白TIFF或BMP檔案格式。目前則因個人電腦處理能力大幅提升及改善,OCR也已能處理JPG格式。而為確保辨識的精確性並提升辨識效率,建議將彩色或灰階文件圖檔進行影像處理,取得較佳的影像格式(150~200dpi、黑白TIFF),以利OCR作業之進行。目前測試結果顯示有利OCR之圖檔格式依序為:黑白TIFF G4、150dpi;黑白TIFF G4、300dpi;全彩JPG/TIFF、300dpi。黑白圖檔因文字與底色的反差明顯度大於彩色圖檔,故OCR辨識度較高;而在同樣能進行OCR作業情況下,黑白TIFF G4、150dpi則因檔案體積及佔用資源空間較小,故較優於黑白TIFF G4、300dpi進行OCR文字辨識。
|
圖檔格式
|
利於OCR辨識程度(依次排序)
|
|---|---|
|
黑白TIFF G4、150dpi
|
反差度高、體積較小
|
|
黑白TIFF G4、300dpi
|
反差度高
|
|
全彩JPG/TIFF、300dpi
|
底圖與文字反差不明顯,對OCR辨識造成干擾
|
(一)確立檔案格式
(二)後設資料需求訪談
(三)訂定後設資料規範
將各類型資料加以分析比較之後,即可依照各典藏品特性來訂定後設資料規範與欄位建置;由於聯合目錄所採用的是都柏林核心集(Dublin Core,簡稱DC﹞做為核心欄位,其普遍性雖然可以處理異質資料庫間的共通,但不同的媒介與計畫間應有適用於該主題更需被凸顯的核心欄位,由此整合的核心欄位再行對應DC欄位,並搭配個別資料庫欄位的分析,將可提高呈現內容的目錄價值。
1.孫正宜、林信成,〈中文報業數位化技術與現況探討-聯合知識庫數位化經驗〉,頁3~4。
[18] 一、色彩校正
[19] 二、數位化掃描技術
[20] 三、光學文字辨識技術
(一)儀器之色彩校正
色彩校正之目的在於充分保留報紙期刊的原狀,尤其是色彩以及文字資訊部分,讓使用者能從閱覽數位化檔案便能獲取與原物件相同之資訊內容,並了解期刊報紙在掃描當時的保存狀況為何。而色彩校正也一直是電腦繪圖及印刷最困難亦最不易解決的問題,因電腦螢幕上的顏色有許多根本就無法印出來,或者有嚴重的色偏等,其每一環節皆環環相扣,從螢幕、掃描器至輸出到印刷,每一層轉換步驟都有色偏的問題。造成色偏之因素如下:
3. 印表機、印刷機:依然必須執行色彩校正才能在可能範圍內得到最佳的輸出品質。
(二)色彩校正方式
(四)輸出應用模式
.jpg)
.jpg)
(二)OCR技術與產品現況
3. 全景軟體
4. 清華文通
(三)OCR技術與實際操作
2.OCR技術分析:
A.影像處理
B.版面分析
.jpg)
.jpg)
C. 字元切割
3. 辨識範例說明:
.jpg) |
|
|
橫式中英文夾雜 (彩色JPG)
|
橫式中英文夾雜 (黑白TIFF)
|
.jpg) |
.jpg) |
|
直式中文(彩色JPG)
|
直式中文(黑白TIFF)
|
.jpg) |
.jpg) |
|
直式表格(彩色JPG)
|
直式中日文(黑白TIFF)
|
.jpg)
本文以實地採訪方式進行OCR辨識軟體的操作過程與結果分析,其中因全景軟體版本無商業發行版可茲比較,而北京漢王則無發行台灣版,故本文在此針對台灣的力新國際、蒙恬科技以及大陸清華文通三家廠商軟體進行操作介面、辨識速度及效果之測試及研究。下列為OCR軟體測試系統版本:丹青中英日文文件辨識系統4.5、蒙恬認識王專業版V3.1、清華TH-OCR 2003錄入工廠。
.jpg)
圖六、清華軟體辨識表格內容及框線
.jpg)
圖七、清華軟體─可移動式橫隔線
|
|
丹青中英日文文件 辨識系統4.5 |
蒙恬認識王 專業版V3.1 |
清華TH-OCR 2003錄入工廠 |
|
|---|---|---|---|---|
|
操作介面 |
較簡單 |
較簡單 |
較繁複 |
|
|
辨識種類 |
繁體中文 |
可,辨識率97% |
可,辨識率91.5% |
可,辨識率97% |
|
簡體中文 |
可 |
可 |
較佳 |
|
|
英文 |
可 |
較差 |
較佳 |
|
|
中英混合 |
較差 |
較差 |
較佳 |
|
|
日文 |
可,辨識率<50% |
不支援 |
較佳,辨識率90% |
|
|
表格 |
較差 |
較差 |
較佳 |
|
|
辨識速度 |
快 |
快 |
稍快 |
|
|
輸入格式 |
*.pcx/*.tif/*.jpg/*.bmp |
*.pcx/*.tif/*.jpg/*. bmp/*.eps/*.msp/*. png/*.psd/*.tga/*.wmf |
*.tif/*.bmp/*.pcx/*.fax/*.jpg |
|
|
儲存格式 |
*.txt/*.rtf/*doc./*xls./ *slk./*csv./*html |
*.txt/*.doc/*.xls/*.html |
*.rtf/*.html/*.txt/ *.jda/*.wps/*.pdf |
|
伍、後設資料與資料庫建置
[24] 一、後設資料與XML
[25] 二、資料庫建置
(一)Metadata釋義與目的
後設資料主要用途在於對無文字敘述的物件,例如實體的書畫、雕塑品或者數位影像、聲音、視訊資料以及平面書籍等提供檢索功能,其真實涵義在於針對資訊的內容與外觀等特性作適當性的描述,就它的意義和功能來說,其實就是一種電子目錄(electronic catalogue),而編制目的即為描述資料的內容和特色,進而達成資料的檢索。在兼顧後設資料標準、實際著錄需求與資訊系統投資的情況下,後設資料標準並不適合當作各單位共通的著錄規範或資料庫規格,而比較適合做為某特定領域典藏資料交換與查詢介面的標準。因此各單位可保留各自所需的著錄項目,再透過對應關係轉為領域內共通的後設資料標準交換格式來交換典藏資料,才可達到後設資料標準國際化的目標。
後設資料約可分為兩類,一種類型為描述資源或知識的資料,此類後設資料並無明顯的標誌或符號,而是一種組織或表達知識的架構方式,例如日常生活中文書編撰所使用的文章組織架構與編排格式皆屬之。另一種類型為結構化與半結構化的描述資料,意指資料是以電腦能了解的結構方式所表達,例如資料庫內所定義的欄位資料就屬於結構化描述資料,而可擴展標記語言(Extensible Markup Language,簡稱XML)與超文字標記語言(Hypertext Markup Language,簡稱HTML)等則為半結構化描述資料,可提供使用者有彈性的資料表達結構。
就後設資料分析的模式而言,中央研究院後設資料分析小組建議從人、事、時、地、物五個角度來思考後設資料應包含哪些著錄項目,因此應結合與典藏物品本質相關的資料及外在資料兩者間的資訊關係,以分析後設資料應包含哪些著錄項目。同時透過管理(administration)、取用(access)、保存(preservation)、應用(use of collections)等四個層面去思考建立後設資料的用途與後設資料使用者之需求,以使後設資料的分析盡可能包含各層面的需要。後設資料應滿足以下需求:
1. 促使系統互通,而不僅僅是提供摘要性資訊。
後設資料可根據其在使用時功能性(Functionality)的不同,分為管理(Administrative)、描述性的(Descriptive)、保存(Preservation)、用途(Use)和技術性的(Technical)等五大類Metadata(表5)[26] [5]。
|
類型
|
定義
|
例子
|
|---|---|---|
|
管理的
(Administrative)
|
資源的管理(Metadata used in managing and administering information resources)
|
物件權限、位置資訊、版本控制
|
|
描述性的
(Descriptive)
|
資源的描述及識別(Metadata used to describe or identify information resources)
|
編目資料、超連結、使用者註解
|
|
保存(Preservation)
|
資源的保存管理(Metadata related to the preservation management of information resources)
|
資源的實際狀態文件、原件、數位物件的保存文件
|
|
用途(Use)
|
資源的使用層次及類型(Metadata related to the level and type of use of information resources)
|
展示紀錄、使用紀錄、內容重複使用及多版本資訊
|
|
技術性的(Technical)
|
描述系統及Metadata如何運作(Metadata related to how a system function or Metadata behave)
|
軟硬體文件、數位化資訊
|
就新聞主題各計畫進行不同數位化物件而言,後設資料可能包含文字、畫面、聲音以及影像等多媒體資訊,而本文以針對期刊報紙文字型後設資料作說明。物件本身內容的文字後設資料包含文字訊息,而非內容本身的文字後設資料則有文字的種類、頁數、文字的形成,以及其他有關章節數目與段落數目等資訊。文字也可以被加以注釋,雖然注釋大多用於聲音和影片資料,然而大量文字資料也需要包含重要資訊的注釋,尤其是以網頁為基礎的系統,可以利用連結來取得特定被檢視的文字資料注釋。注釋也可以被視為補充的資料,並且可被視為一種後設資料。文字資料的重大發展為國際標準組織(International Organization for Standardization,簡稱ISO)於1986年制訂了標準通用標記語言(Standard Generalized Markup Language,簡稱 SGML)。因為SGML,文字資料可以輕易地被標示並且截取出後設資料,可標示出文字資料中所包含的人與發生地點,因此可以用關鍵字來擷取後設資料,SGML後來即演變為XML。
(二)XML的應用
XML同時也具有以下缺點:
2. 用於新聞領域的XML[27] [6]
(一)數位化資料儲存與管理
(二)撰寫規格需求書
(三)資料庫設計
(四)資料庫維護
若是定期持續更新典藏品的資料庫,其資料庫維護必須由專人隨時待命,讓資訊內容持續更新與即時回訊,使系統安全維持穩定運作,以利資料庫的維護工作。這方面必須特別注意資料庫管理人員的工作交接。
2.洪淑芬,《文獻典藏數位化的實務與技術》,頁96。「棉質手套」:如果所處理之事項多為搬移作業,接觸部分多為資料之外包裝,或是翻動之資料狀況良好,極易翻掀,則棉質手套可防汗垢沾上資料,但是,棉質手套必須隨時清洗乾淨,避
免使用已髒污之手套。「膠質手套」:最好是手套內無粉者。膠質手套不透氣,穿戴時間稍長會感到不舒服,但對於有蟲蛀之資料,必須使用表面光滑之膠質手套,以防止資料上的蟲損之處,黏附於手套上,反而對資料造成傷害。
3.曾逸鴻,《光學文字辨識(OCR)技術整理報告》,頁2。
4.曾逸鴻,《光學文字辨識(OCR)技術整理報告》,頁3。區塊切割有兩種方法:「遞迴投影法」(Recursive projection analysis)或「相連元件偵測法」(Connected component detection)。若文件屬於版面較傾斜者,則前者「遞迴投影法」較無法獲得準確的切割位置。
5.曾欣怡、潘育潔,〈新聞傳播多媒體資料庫Metadata分析研究〉,頁B3-4。
6.林信成、康珮熏,〈報紙新聞數位典藏Metadata 轉換系統之設計與應用〉,頁B2-1。
2. 原件製作成微縮膠卷
3. 原件製作成單張黑白底片
|
數位化物件
|
可使用設備
|
|---|---|
|
期刊報紙原件
|
1.桌上型平台式掃描器 4.滾筒掃描器
2.桌上型自動進紙式掃描器 5.仰面式書籍掃描器
3.桌上型無邊縫書籍掃描器 6.專業多用途掃描器
|
|
微縮膠卷
|
微縮膠卷掃描器(單頁式/捲片式)
|
|
單張黑白底片
|
《翻拍類》
1.數位相機 2.數位機背
|
|
《掃描器類》
1.具備光罩之桌上型掃描器 2.專業多用途掃描器
|
1. 掃描器類
2. 翻拍類
|
桌上型平台式掃描器 |
具備光罩之桌上型掃描器 |
|
桌上型自動進紙式掃描器 |
桌上型無邊縫書籍掃描器 |
.jpg)
.jpg)
.jpg)
.jpg)
|
滾筒掃描器 |
微縮膠卷掃描器 |
|
仰面式書籍掃描器 |
專業多用途掃描器 |
|
數位相機 |
數位機背 |
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
.jpg)
|
適用性
機型
|
掃描尺寸
|
掃描
速度(A2以上)
|
最高
解析度
|
垂直線是否
變形
|
適合物件
|
大量生產
|
傷害
情形
|
機器
單價
|
|---|---|---|---|---|---|---|---|---|
|
桌上型平台式掃描器
|
A3
|
|
600
|
不會
|
單張
|
可
|
須拆書
、接圖
|
10萬~
20萬
|
|
桌上型平台式掃描器
|
A4
|
|
600
|
不會
|
單張
|
可
|
須拆書
、接圖
|
3,000~6,000
|
|
具備光罩之
桌上掃描器
|
A3
|
|
600
|
不會
|
單張
|
可
|
須拆書
、接圖
|
15萬
|
|
桌上型自動
進紙式掃描器
|
A3
|
|
600
|
不會
|
單張
|
可
|
須拆書
、接圖
|
20萬
|
|
桌上型無邊縫書籍掃描器
|
A3
|
|
600
|
不會
|
單張
、書籍
|
可
|
書頁容易脫落
|
8~10萬
|
|
滾筒掃描器
|
A1
|
慢
|
4800
|
不一定
|
單張
|
可
|
離心力
|
100萬
|
|
微縮膠卷
掃描器
|
|
|
|
不會
|
微縮
膠卷
|
可
|
|
300~
350萬
|
|
仰面式書籍
掃描器
|
A1
|
一分鐘以內
|
300
|
不會
|
單張
、書籍
|
可
|
光線過熱、紅/紫外線傷書、玻璃壓力
|
450~
600萬
|
|
專業多用途
掃描器
|
A1
|
一分鐘以內
|
1600
|
不會
|
平面物件、可平放立之體物件
|
可
|
傷害程度較低
|
160~
350萬
|
|
數位相機
|
視原件大小
|
快
|
|
邊角可能變形
|
不限
|
不可
|
光線過熱、紅/紫外線傷書
|
20~
40萬
|
|
數位機背
|
視原件大小
|
快
|
|
邊角可能變形
|
不限
|
不可
|
光線過熱、紅/紫外線傷書
|
100~
150萬
|
|
軟體型號
|
公司廠牌
|
產出地點
|
軟體價位
|
|---|---|---|---|
|
丹青中英日文文件辨識系統4.5
|
力新國際
|
台灣
|
$6,600
|
|
蒙恬認識王專業版V3.1
|
蒙恬科技
|
台灣
|
$3,990
|
|
無發行商業版
|
全景軟體
|
台灣
|
無發行商業版
|
|
清華TH-OCR2003錄入工廠
|
清華文通
|
大陸
|
$120,000
|
|
無發行台灣版
|
北京漢王
|
大陸
|
無發行台灣版
|
數位化成本包含設備、人工、維修等,也依照方案不同而有所變動。數位化方案有計畫單位自行數位化及委外廠商進行數位化。本文先以單位自行數位化方案為例說明,因委外方案必須考慮公開招標金額,較前者複雜,故暫不列於此詳述。
1. 掃描物件為裝訂式期刊(A4尺寸)
2. 掃描物件為現今發行之報紙(A1尺寸)
每張成本=(102,222+30,000*2)/10,800=15元/張
「期刊報紙全文輸入工作流程參考標準」希望能對欲進行數位化之機構單位或個人蒐藏者提供明確而清楚的數位化流程與整體概念,期待藉由淺顯易懂的標準作業程序來提升數位化工作效率,並降低初步摸索數位化工作流程的時間,使各機構單位在教育訓練上面花費較短時間與人力且有效率地進行數位化工作。由此工作流程參考標準與實際進行工作流程作評估與比較,並從中截長補短,以加速並確實掌握數位化之工作進度。對於以期刊、報紙或平面書籍等作為數位化物件的計畫單位,希冀本文中的光學辨識系統OCR研究與分析能提供執行全文輸入時作參考,以避免浪費過多的人力與時間。因此本文「期刊報紙全文輸入工作流程參考標準」盼望能有以下效益:
「期刊報紙全文輸入工作流程參考標準」因研究範圍有限,故無法針對缺字技術與委外情形做進一步的分析,且礙於OCR辨識軟體發行版本的限制,如全景軟體無發行商業版、北京漢王則無發行台灣版,以致無法使台灣、大陸的光學文字辨識系統作更深入的研究與全面性的評估,此點深感遺憾,然而,本文也希望在現有的設備及軟體技術之下,提供一份適當的數位化工作流程參考標準以供各界參考。展望未來,因為OCR軟體的應用仍然持續在進步中,印刷體辨識系統已逐漸成熟且應用廣泛,因此,我們仍可樂觀預見多種全文輸入數位化的方式,甚至是手寫體辨識或同步語音辨識的發展,在不久的將來,其軟體及技術皆能趨於穩定且具普及性,以期高效率地輸入大量文字資料,並提供全文檢索及查詢等便利性。
捌、結語
數位化工作流程在整體規劃上必須是嚴謹而縝密的,在執行過程中也盡可能使每一個環節具有連貫性且可調整,並能充分掌握數位化的進度。在科技日新月異的今天,機器硬體設備不斷地升級更新,或許每一份參考作業流程只能配合當時的設備與技術,但我們仍然寄予無限的希望,對於數位典藏的未來需要更多的努力與試驗,進而不斷修正而找出最適合物件本身進行的數位化方案。
〈[33] 目錄〉
玖、參考文獻
1.林淑芬,〈期刊文獻資訊網新服務-「全國報紙資訊網」及「國家圖書館期刊影像資料庫」上線服務〉,民國92年2月。http://www.ncl.edu.tw/pub/c_news/92/05.html
2.林信成、康珮熏,〈報紙新聞數位典藏Metadata 轉換系統之設計與應用〉,《中文媒體數位典藏與新聞標示語言研討會論文集》,台北:數位典藏國家型科技計畫,2005年5月,初版,頁B2-1~B2-23。
3.范紀文、何建明,《數位典藏系統與工具–輕鬆建立屬於您的典藏管理系統》,2000年。
4.洪淑芬著,《文獻典藏數位化的實務與技術》,台北:數位典藏國家型科技計畫 訓練推廣分項計畫,2004年2月,初版。
5.吳政叡,〈Dublin Core繁體中文譯介〉,http://dimes.lins.fju.edu.tw/dublin/
6.孫正宜、林信成,〈中文報業數位化技術與現況探討-聯合知識庫數位化經驗〉,收錄於《2003年資訊科技與圖書館學術研討會論文集》,民國92年5月,頁73~93。
7.莊樹華、張凱達,〈檔案數位影像製作之流程與管理〉,收錄於《檔案季刊》,Vol 2:1,民國92年3月,頁57-67。
8.陳同孝、張真誠,〈淺談影像壓縮〉,收錄於《資訊與教育》,Vol 63,民國86年,頁20-27。
9.陳心渝,〈JPEG 2000及浮水印批次套印技術〉,數位典藏國家型科技計劃技術發展組,2005年。
10.黃國倫、蕭人豪、李家豪、陳心渝,〈數位典藏系統缺字處理及應用〉,收錄於《第三屆數位典藏技術研討會論文集》,民國93年8月,頁79-85。
11.黃耀輝,〈淺談中文字及其輸入、辨識之比較〉,收錄於《中研院計算中心通訊》,Vol 14:25,民國87年7月,頁233-234。
12.曾士熊,〈中文輸入法概述〉,收錄於《中文輸入法專題》,Vol 13:8,民國86年4月。
13.曾逸鴻,《光學文字辨識(OCR)技術整理報告》,台北:國防部電訊發展室,民90 年1 月
14.曾欣怡、潘育潔,〈新聞傳播多媒體資料庫Metadata分析研究〉,《中文媒體數位典藏與新聞標示語言研討會論文集》,台北:數位典藏國家型科技計畫,2005年5月,初版,頁B3-1~B3-43。
15.廖運尚,〈國史館採用無失真壓縮實作經驗談〉,收錄於《國史館館刊》,Vol 35 2003年12月,頁184-200。
16.謝育平、吳政泓、項潔,〈可攜式字集資源架構─用以解決缺字問題〉,收錄於《第三屆數位典藏技術研討會論文集》,民國93年8月,頁71-78。
17.Konstanze Bachmann,《藏品維護手冊》,劉藍玉譯,台北:五觀藝術管理,2001
18.《新聞主題小組數位化工作流程》,台北:數位典藏國家型科技計畫 內容發展分項計畫,2005年1月,初版。
19.CBETA中華電子佛典協會,《CBETA電子佛典集成》,2005年2月,[34] http://w3.cbeta.org/index.htm
20.Iannella, R., Mostly Metadata, A Bit Smarter Technology,
[35] http://www.dstc.edu.au/RDU/reports/VALA1998/
21.Baca, M. Ed., Introduction to Metadata: Pathway to digital information. J. Paul Getty Trust.
22.W3C,Extensible Markup Language (XML),[36] http://www.w3.org/XML/
〈[37] 目錄〉
拾、附錄
[38] 附錄一、期刊影像掃描檔案編碼原則
[39] 附錄二、報紙影像編碼原則
[40] 附錄三、國家圖書館數位化檔案建議格式
[41] 附錄四、色彩校正流程
[42] 附錄五、辨識技術
致謝
本文「期刊報紙全文輸入工作流程參考標準」是作者任職於數位典藏國家型科技計畫─內容發展分項計畫,擔任新聞主題小組負責助理期間所進行研究完成。在研究過程中,特別感謝磁軒資訊媒體行銷有限公司李夙總經理及連憶親小姐接受作者採訪,協助OCR辨識軟體的操作過程與結果分析;同時亦感謝國家圖書館林淑芬編輯、聯合報知識庫孫正怡組長、大葉大學曾逸鴻助理教授分享寶貴的實務經驗或技術手冊等。
最後,感謝本計畫主持人林富士先生及共同主持人邱澎生先生對於撰寫SOP期間的叮嚀與指導,以及計畫內工作同仁─曾欣怡對於本文第伍章「後設資料與資料庫建置」之資料提供與潤稿,另外,包括林彥宏、林慧菁、陳美智、林淑惠、蔡欣芸、呂俊毅等人的協助與校稿,在此一併致上謝意。
參與研發單位:國家圖書館
提供單位:國家圖書館
使用單位:國家圖書館
國家圖書館閱覽組(期刊)93 年4 月第13 次修訂
1. 期刊批次掃描以掃描全本期刊為原則。即時期刊影像掃描則以單篇為掃描單位,但皆適用本編碼原則。本掃描之期刊影像需與本館相關資料庫系統自動產生關連,以利影像調閱及文獻傳遞,故編碼過程需配合本館「中華民國出版期刊指南系統」、「中華民國期刊論文索引影像系統」、及「國家圖書館新到期刊目次服務系統」等書目資料的著錄原則。資料庫網址:http://readopac.ncl.edu.tw/
2. 每本期刊其檔案目錄分為三層:期刊識別號、卷期總號、出版年月。再以頁碼區分檔名,檔名中英文字母皆為小寫。
例: 研考月刊第1 卷1 期民國85 年1 月第1 頁→00000001/1n1/8501/00000001.tif
說明:
2.1 第一層:期刊識別號
共 8 bytes,由中華民國期刊指南系統查出期刊識別號。
例: 研考雙月刊 → 00000001
2.2 第二層:卷期總號
由期刊之封面與書名頁查出該期之卷期總號時參考本館「中華民國期刊論文索引影像系統」及「國家圖書館期刊目次系統」之卷期著錄方式。
卷期總號長度不受限於8bytes,應完整編碼。
2.2.1 凡卷期總號中含有特殊符號或文字者,請以下列英文字母代替之。
卷 : → n 例: 3 卷1 期 3:1 →3n1
合刊 / → x 例: 4、5 期合刊 4/5 →4×5
合刊 - → - 例: 62 卷1-2 期 62:1-2 →62n1-2
總號 = → e 例: 3 卷1 期總號495
3:1=495 →3n1e495
試刊號, 試刊 →t
創刊號 → f
第十章 典藏品識別碼暨數位檔案命名規範
1.10.2.2
特刊 → s 例: 特刊16 → s16 5(特刊) → 5s
復刊 → r 《 r 之後請勿加_ 》 例: 復刊16 →r16
增刊 → a
專刊 → b
革新 → j
索引 → i 例: 1-12 期索引 → i1-12
上 → u 例: 70 期上 70(上) → 70u 去除括號()
中 → m 例: 70 期中 70(中) → 70m 去除括號()
下 → d 例: 70 期下 70(下) → 70d 去除括號()
外編、別冊 → c 例: 別冊1 →c1
外編第四種上冊 →c4u
副刊、附冊、附輯 → g
補編 → h
總目錄 → o(英文)
新,新刊 →y 例: 新3:2 →y3n2
凡無卷期者,請輸入0(數字)
春 → sp 例: 1994 春季號 1994:春 → 1994nsp
夏 → su 例: 87 夏季號 87:夏 → 87nsu
秋 → au 例: 84 秋季號 84:夏 → 84nau
冬 → wi 例: 84 冬季號 84:冬 → 87nwi
2.2.2 凡卷期外有標示學科分冊者代碼如下:
特 刊 → s
例 第5 期特刊 5(特刊) → 5s
人文分冊 →hu
例: 1 卷1 期人文分冊 1:1(人文分冊) →1n1hu
人文社會篇 →hs
科技人文篇 →sh
社會科學分冊 →so
例: 1 卷1 期社會科學分冊
1:1(社會科學分冊) →1n1so
管理科學分冊 → ma
例: 1 卷1 期管理科學分冊
10-2 期刊影像掃描檔案編碼原則(原10-2 更新)
1.10.2.3
1:1(管理科學分冊) →1n1ma
文學院 →li
例: 35 期文學院 35(文學院) →35li
理學院 →sc
例: 35 期理學院 35(理學院) →35sc
工學院 →te
例: 35 期工學院 35(工學院) →35te
管理學院 →ma
例: 35 期管理學院 35(管理學院) →35ma
社會科學學院 →so
例: 35 期社會科學學院 35(社會科學學院) →35so
農學院 →ag
例: 35 期農學院 35(農學院) →35ag
文學部門 →li
例: 14 期文學部門 14(文學部門) →14li
商學部門、商學‧管理部門 →bi
例: 14 期商學部門 14(商學部門) →14bi
理工部門 →sc
例: 14 期理工部門 14(理工部門) →14sc
區域研究部門 →ar
例: 13 期區域研究部門 13(區域研究部門) →13ar
文商理工部門→lb
例: 16 期文商理工部門 18(文商理工部門) →16lb
文學與商學部門 →li
例: 12 期文學與商學部門
12(文學與商學部門) →12li
社會科學學院 →so
例: 35 期社會科學學院 35(社會科學學院) →35so
科技‧醫學篇 →st
例: 32 期科技‧醫學篇 32(科技‧醫學篇) →32st
文史‧社會篇→ lh
例: 32 期文史‧社會篇 32(文史‧社會篇) →32lh
第十章 典藏品識別碼暨數位檔案命名規範
1.10.2.4
軍事社會特刊→ mi
中國系列 → ch
行政革新專號→ ad
2.2.3 凡無卷期編號者, 掃描時編碼為0
2.3 第三層:出版日期
由期刊之封面與書名頁查出該期之出版日期,同時參考本館「中華民國期刊論文索引影像系統」、「國家圖書館期刊目次系統」之日期著錄方式,以求一致性。出版日期長度不限於8bytes,以詳盡著錄為原則,如年月日。但須配合以上系統之著錄方式。出版日期採民國紀元。
2.3.1 凡出版年月日中含有“民”字者,請省略不予註記。
例: 民87 年1 月 →8701
2.3.2 年月日間之“‧”號逕行省略,不輸入亦不空格
例: 87.01 →8701
2.3.3 下列文字請以英文字母代替之:
春 → sp 秋 → au
夏 → su 冬 → wi
例: 民87.春 →87sp
2.3.4 合刊的年月處理如下
23-24 民76.11-12 → 23-24 76.11-12
民75.12-76.01 → 7512-7601
3. 頁碼(檔名)編碼
頁碼檔名長度一般以8bytes 為原則,少數特例可長達9bytes。
例如:第100 頁 → 00000100.tif
第100 頁後之插頁→000100_1.tif
以內文頁碼加上“.tif”作為檔名。如內文第 1 頁,其檔名為
“00000001.tif”。
注意事項:
3.1 內文第 1 頁前面之各頁(即非正文部份),如封面、目次、封底等,請自封面起依序計數,頁碼第一位加“ a”以區別之,如: a0000001.tif ,a0000002.tif…
3.2 內文後面多出且原本未編頁碼之各頁,請依原文最後之頁碼繼續編號下去即可。
3.3 原文編有頁碼或實際有佔頁碼但未編頁碼之空白頁或廣告頁等請仍依原順序掃入。
3.4 原文未編頁碼且為多餘之空白頁請予跳過不掃。
3.5 內文中之插頁,如原文未編頁碼,則於接續之前頁後加“_”連續編碼。如:
在86 頁至87 頁間插頁 2 頁但未編碼,請以“000086_1.tif”、“000086_2.tif”編號。
3.6 期刊分左、右版次者,以右版為主為原則,但仍需先查核期刊索引及期刊目次系統之編碼,以配合之。左版頁碼需以L(小寫)區別,右版頁須以R(小寫)區別。
如:頁左33-左40“,檔名為“L0000033.tif”~L0000040.tif
如:頁右12-右20“,檔名為“R0000012.tif”~R0000020.tif
注意:一本期刊不須同時區分左、右版,應取其一為主,另一版加註區別即可,原則上以加註左版者居多。但須配合國圖期刊索引與目次系統之著錄方式。
3.7 凡標明“頁中”或“中”者請轉換為“m”。如“頁中13-14”,輸入檔名為“m0000013.tif”~“m0000014.tif”
3.8 凡正文中每篇文章皆以”1”起頁者,依篇序頁碼前分別以 ()冠各篇序號,頁碼轉換時規則如下:
□□ □□ □□□□. tif
附錄 篇 頁 碼
例: 第一篇1-17 頁
(1)1-(1)17 →00010001.tif-00010017.tif
第二篇1-18 頁
(2)1-(2)18 →00020001.tif-00020018.tif
第21 篇1-18 頁
(21)1-(21)18 →00210001.tif-00210018.tif
頁(A)27-(A)33 → 00010027.tif-00010033.tif
頁(y)1-(y)5 → 00250001.tif~00250005.tif
附錄(a)7~附錄(a)10
→ap010007.tif-ap010010.tif
*附錄 → ap
*a、b、c……依英文順序轉換例a=01 b=02 ……z=26
第十章 典藏品識別碼暨數位檔案命名規範
1.10.2.6
3.8.1 前述情形若又有左右起頁之橫直版之不同,則須多加一碼,冠以L 或R 分別區分左起頁版或右起頁版,此種編碼會有9 位。頁碼轉換時規則如下:
R□□□□□□□□. tif
L□□□□ □□□□. tif
例: 左起頁 第一篇1-17 頁
L (1)1-(1)17 →L00010001.tif-L00010017.tif
右起頁 第二篇1-18 頁
R(2)1-(2)18 →R00020001.tif-R00020018.tif
3.9 凡正文有兩組頁碼標示者,一組各篇從1 編頁,一組為總頁碼者,依總頁碼編。但若有兩組總頁碼,一組自1 編,一組是接前期續編者(頁數號碼較大),則依第一頁起始者編,但仍應先查核本館期刊索引及期刊目次系統之著錄方式,或請示館方負責人員。
3.10 凡頁碼編排有疑義應先參考期刊索引系統或期刊目次系統登錄方式,如仍有問題應先請示館方負責人員。
參與研發單位:國家圖書館
提供單位:國家圖書館
使用單位:國家圖書館
國家圖書館閱覽組(期刊)民國90 年1 月第二次修訂
1. 本報紙編碼原則適用於紙本報紙掃描為影像檔,及微縮捲片(35mm)報紙轉製影像檔之檔案編碼處理。
2. 紙本報紙影像掃描以每日為單位。
3. 其影像檔案目錄分為二層:報紙識別號、出版日期。再以版次區分檔名,檔名中英文字母皆為小寫。
例:臺灣新生報 民國50 年1 月1 日 第1 版
→ /68600106/19610101/00000001.tif
3.1 報紙識別號
檔名長度為 8 bytes,由本館中華民國期刊指南系統查出報紙識別號。
例:臺灣新生報
識別號 → 68600106
3.2 出版日期
不限檔名長度,原則上以完整著錄為原則,並將出版日期轉換為西元紀元。
例:民國50 年1 月1 日 → 19610101
3.3 版次
檔名長度共8bytes,以一版面單位為一頁。
例:第一版 → 00000001.tif
非定期專刊、增刊、特刊 例: 專刊4 版 → s0000004.tif
單獨編頁碼之廣告 → ad 例:廣告第8 版→ ad000008.tif
3.4 編碼實例:
民生報
現代生活:a0000003.tif
體育戶外:b0000005.tif
影視娛樂:c0000006.tif
第十章 典藏品識別碼暨數位檔案命名規範
1.10.6.2
影視快訊:cs000007.tif
家庭消費:d0000008.tif
旅遊專刊:e0000009.tif
行程專輯:f0000010.tif
大成報
體育報:b0000002.tif
影劇報:c0000003.tif
經濟日報
金銀島:sb000003.tif
科技島:ss000005.tif
其他專刊:s0000003.tif
同一天第二種專刊 s1000004.tif
同一天第三種專刊 s2000003.tif
China Post
增刊:s0000004.tif
|
檔案格式
|
建議規格
|
說明
|
|---|---|---|
|
文字檔
|
||
|
資料永久保存格式
|
檔案格式: TIFF |
將資料數位化典藏,保持原有風貌。提供使用者作重製、壓縮處理或其他圖像處理交換之用。
|
|
網路下載格式
|
檔案格式:JBIG or JBIG2 |
提供使用者網路上觀看及列印用。
|
|
預覽影像
|
檔案格式:GIF |
提供使用者預覽及選擇欄位用。
|
|
影像檔
|
||
|
資料永久保存格式
|
檔案格式:TIFF |
將資料數位化典藏,保持原有風貌。提供使用者作為重製、壓縮處理或其他圖像處理交換之用。
|
|
資料服務/參考格式
|
檔案格式: JFIF(JPEG交換格式) |
提供使用者網路上觀看及列印用。
|
|
縮圖影像
|
檔案格式:GIF |
提供使用者預覽及選擇欄位用。
|
資料來源:專業多用途掃描器代理商 ─ 磁軒資訊媒體行銷有限公司


資料來源:大葉大學資訊管理系 曾逸鴻助理教授
《光學文字辨識(OCR)技術整理報告》
當字元切割完成,即可將每個字元影像丟入辨識引擎做辨認。最基本的辨認方式,即是將字元影像做大小的正規化(Normalization),然後與資料庫中每個中文字的影像(亦已經過正規化)做模版比對(Template matching),計算相對位置的顏色是否相同,找出差異最小者即為辨識結果。此種模版比對方式為確實掌握文字特性,且所需的記憶體空間較大,比對速度也慢,所以並不被大多數OCR系統所採用。在辨識引擎的內部技術,我們可分特徵抽取、特徵比對與加速技術三部分來描述。
1. 特徵抽取~
特徵抽取是辨識引擎最重要的一節,要找到最少的特徵,來得到最佳的辨識效果,常採用的特徵可分為結構特徵與統計特徵,結構特徵包括文字影像內的線段(line segment)、筆畫(stroke)、曲線(curve)、環路(loop)等,通常文字影像需先經過細線化(thinning),將字元轉成只剩一個像素的寬度,再來抽取結構特徵。經過實驗,利用結構特徵所建構的OCR辨識引擎,較適合辨認印刷清楚且筆畫較少的字元,不太適合於建構商用OCR軟體。統計特徵則將文件影像的像素分佈作分析,利用大量的學習影像來計算特徵向量的平均值與變異度。只要學習影像收集的夠完整、數量夠多,利用統計方式建構出的OCR辨識引擎較能做較廣泛的應用。常採用的統計特徵如下:
(1). 筆畫數目(Stroke count)特徵:對於某個參考點(reference point),往上下左右延伸,計數可通過多少筆畫。此處筆畫的定義為,延伸線上的點「由白變黑」再「由黑變白」,算是一個筆畫。因此對於每個參考點,我們可得到四個特徵值。
(2). 邊緣像素數目(Contour pixel count)特徵:由於不同文件切出的字元影像擁有不同的筆畫寬度,此特徵乃計數字元的邊緣點數目。
(3). 邊緣方向數目(Contour directional count)特徵:考慮邊緣像素,計算四個方向(水平、垂直、左撇、右捺)的邊緣點數目,可得到四個特徵值。
(4). 網眼特徵(Cellular feature):對於某個參考點,往上下左右延伸,計算要延伸多長的距離始可碰到第一個黑點,可得到四個特徵值。
(5). 周圍背景面積 (Peripheral background area, PBA)特徵:由字元邊界往內走,走到第一個黑點便停止,記錄其距離,將所有距離累計,即為此特徵值。由於此種特徵不管字元中心部分,只描述其周圍的白色背景面積,適於辨認因墨水過多導致中心部分容易糊成一坨的字元。
(6). 周圍背景差異 (Peripheral background difference, PBD)特徵:與PBA類似的計算法,只是此特徵記錄的事兩距離的差異,而不是累計距離。因此,可分辨雖然累積距離相同,但距離先長後短與先短後長的不同。一樣適於辨認中心部分易模糊的字元。
(7). 橫越個數特徵 (Crossing counts feature):由字元左邊界往右邊界走,計算通過的筆畫數,加以累計,垂直方向亦同。
(8). 投影特徵 (Projection feature):將字元影像分別往四個方向(水平、垂直、左撇、右捺)投影,設適當的門檻值,分別在此四個投影圖中,計算投影量高於門檻值的筆畫的個數,當作特徵值。
另外,由於要找到效果很好的特徵不易,一旦找到適當的特徵,為求更精準描述字元,通常會將字元做切塊,例如邊緣方向數目特徵雖然只有四個特徵值,若先將字元切成8×8塊,在每一塊抽出四個特徵值,則此字元總共可得到8×8x4=256個特徵值。字元的切塊方式有兩種:
(1). 等分(uniform)切割:直接以字元的寬或高等距切成數等分。
(2). 不等分(non-uniform)切割:先將所有黑點往X軸投影,將投影圖切成數份,使得每一份內的的黑點數目相同,在對Y軸投影,以同樣方式切成數份。此方式切出的區塊大小不同,但較可容許手寫字的變異度,及印刷字的雜訊。
2. 特徵比對~
特徵抽取完,成為一個多維的特徵向量(Feature vector) 後,就要與資料庫中經過學習各字(中文字常用字數為5401字)的代表特徵向量 作比對。由於學習與辨識所採用抽取特徵的過程都一樣,因此,比對方式為兩特徵向量間,計算相對維度特徵值的差異和。
假設特徵向量共256維,未知字元影像抽出的特徵向量為 ,字元j的代表特徵向量為 ,其標準差(standard deviation)為 ,計算兩特徵向量差異值 的方法有下列幾種:
(1). Minimum distance:
(2). Euclidean distance:
(3). Cross correlation distance:
(4). Modified Mahalanobis distance:
(5). Li and Yu distance:
3. 加速技術~
由於中文字數量極多,辨識特徵取出的維度亦不少,使得如何加速比對過程,也成為相當重要的研究課題,常採用的方法有下列幾種:
(1). 分群法(Clustering):先以簡單特徵將中文字分成數群,不同群內字元可重複或不重複。未知影像抽完簡單特徵後,先決定此未知影像會落於哪一群,再以較複雜的特徵,與該群內的字元做細部比對。此方式需先決定哪些字元屬於同一群,且不同未知影像只要落於同一群,其細部比對的候選字元均相同。
(2). 候選字選擇法(Candidate selection):此法不必事先決定哪些字元屬於同一群。未知影像抽完簡單特徵,就與所有字元做比對,取前幾名(如前百分之一)再以複雜特徵做細部比對。因此,不同未知影像其細部比對的候選字元必定不同。
(3). 分支界定法(Branch and Bound):前兩種加速法均致力於降低比對的字元數目,因此會降低整體辨識率,此法則設法加速特徵向量的比對速度,主要用於複雜特徵的細部比對過程。首先,先按照重要性將特徵向量的各維特徵值做重排列,以最重要的幾個特徵值與代表特徵向量作距離的計算,按照此累計距離將候選字元的比對順序重排。在來求出未知字元與第一個候選字元的完整距離,以此為一門檻值,在計算第二個候選字元以後的完整辨識距離的過程中,每累計一個維度特徵值的差異時,便與此門檻值做比較,若超過門檻值,則未計算的維度也不用再計算,便可跳到下個候選字。若累計完所有維度得到完整距離,仍未超過門檻值,則將門檻值改為此完整距離。此加速法的最大優點為完全不會降低整體辨識率。
Article printed from 拓展台灣數位典藏: http://content.teldap.tw/index
URL to article: http://content.teldap.tw/index/?p=213
URLs in this post:
[1] 壹、引言: http://content.teldap.tw/index/?p=213&page=2
[2] 貳、數位化工作流程圖: http://content.teldap.tw/index/?p=213&page=3
[3] 參、前置作業: http://content.teldap.tw/index/?p=213&page=4
[4] 肆、物件數位化程序: http://content.teldap.tw/index/?p=213&page=5
[5] 伍、後設資料與資料庫建置: http://content.teldap.tw/index/?p=213&page=6
[6] 陸、設備與成本分析: http://content.teldap.tw/index/?p=213&page=7
[7] 柒、效益與侷限: http://content.teldap.tw/index/?p=213&page=8
[8] 捌、結語: http://content.teldap.tw/index/?p=213&page=9
[9] 玖、參考文獻附錄: http://content.teldap.tw/index/?p=213&page=10
[10] 拾、附錄: http://content.teldap.tw/index/?p=213&page=11
[11] 目錄: http://content.teldap.tw/index/?p=213
[12] 目錄: http://content.teldap.tw/index/?p=213
[13] 一、年度工作規劃: #3-1
[14] 二、數位化執行方式之選擇: #3-2
[15] 三、後設資料之建立: #3-3
[16] [1]: #_edn1
[17] 目錄: http://content.teldap.tw/index/?p=213
[18] 一、色彩校正: #4-1
[19] 二、數位化掃描技術: #4-2
[20] 三、光學文字辨識技術: #4-3
[21] [2]: #_edn2
[22] [3]: #_edn3
[23] [4]: #_edn4
[24] 一、後設資料與XML: #5-1
[25] 二、資料庫建置: #5-2
[26] [5]: #_edn5
[27] [6]: #_edn6
[28] 目錄: http://content.teldap.tw/index/?p=213
[29] 一、數位化設備分析: #6-1
[30] 二、數位化成本分析: #6-2
[31] 目錄: http://content.teldap.tw/index/?p=213
[32] 目錄: http://content.teldap.tw/index/?p=213
[33] 目錄: http://content.teldap.tw/index/?p=213
[34] http://w3.cbeta.org/index.htm: http://w3.cbeta.org/index.htm
[35] http://www.dstc.edu.au/RDU/reports/VALA1998/: http://www.dstc.edu.au/RDU/reports/VALA1998/
[36] http://www.w3.org/XML/: http://www.w3.org/XML/
[37] 目錄: http://content.teldap.tw/index/?p=213
[38] 附錄一、期刊影像掃描檔案編碼原則: #10-1
[39] 附錄二、報紙影像編碼原則: #10-2
[40] 附錄三、國家圖書館數位化檔案建議格式: #10-3
[41] 附錄四、色彩校正流程: #10-4
[42] 附錄五、辨識技術: #10-5
[43] 目錄: http://content.teldap.tw/index/?p=213
Click here to print.