



























語料庫數位化工作流程指南
Tags: 指南, 數位化工作流程, 語料庫數位化, 語言學 發表: 2008-01-09, 點閱: 24,419 , 加入收藏櫃 , 列印
,
列印
,  轉寄
轉寄
想加入的書籤:














貳、語料庫構成技術
(一)概述
語言學是以研究人類語言為對象的學科,牽涉範圍相當廣泛,從生理、心理、物理、數學、地理、哲學、美學、社會學、歷史學、民族學、人類學、工程學各方面等都與語言相關。傳統上,語言學是文化人類學的分支,但現在語言學逐漸自成一格。語言學研究句法和詞語等語言的描述,也研究語言的發展史。而為研究用途的資料,以往只能以單一物品的方式保存,如書籍、報章雜誌…等文本,甚至採集口語資料用的錄音帶等,這些資料在日積月累之後必定會囤積相當的數量,在使用與保存方面都耗費心力,於是結合計算機語言的語料庫就成為一有效的解決方案,並成為語言學理論研究、應用研究和語言工程上不可或缺的基礎資源。
語料庫通常指為語言研究收集,並採用數位形式保存的語言材料,由自然語言或口語的樣本構成,用來表達特定語言或是語言轉變。經過科學標注並具有適當規模的語料庫能夠反映與記錄語言的實際使用狀況。透過語料庫觀察和掌握語言事實,可以分析以及研究語言系統的規律性。
計算語言學於數理語言學興起後約20年也應運而起,此時電子計算機已發展到第四代,成為語言學家的得力助手。計算語言學的目的,是闡明如何利用電子計算機來進行語言研究,其項目有資料統計、情報檢索、研究詞法及句法、文字識別、語音合成、編制機器輔助教學、機器翻譯等等。由於電子計算機儲存量龐大,計算能力精確,作業效能較高,又能用於撰稿、修改、儲存文稿和各種資料,對於語言研究有很大的助益。
語料庫具多種類型,確定類型的主要依據研究目的和用途,這一點往往能夠表現在語料採集的原則與方式。語料庫原則上可以分為四種類型:
(1)異質的(Heterogeneous) : 無特定的語料收集原則,廣泛收集並原樣儲存各種語料;(2)同質的(Homogeneous) : 只收集同一類的語料;(3)系統的(Systematic) : 根據預先確定的原則和比例收集語料,使語料具有平衡性和系統性,能夠代表某一特定範圍的語言事實;(4)專用的(Specialized) : 只收針對某一特殊用途的語料。 除此之外,按照語料的種類劃分,語料庫也可以分為單語(Monolingual),雙語(Bilingual)和多語的(Multilingual)。
(1)異質的(Heterogeneous) : 無特定的語料收集原則,廣泛收集並原樣儲存各種語料;(2)同質的(Homogeneous) : 只收集同一類的語料;(3)系統的(Systematic) : 根據預先確定的原則和比例收集語料,使語料具有平衡性和系統性,能夠代表某一特定範圍的語言事實;(4)專用的(Specialized) : 只收針對某一特殊用途的語料。 除此之外,按照語料的種類劃分,語料庫也可以分為單語(Monolingual),雙語(Bilingual)和多語的(Multilingual)。
語料庫與語言訊息處理有著某種與生俱來的聯繫,以往不了解語料庫方法的時候,在自然語言理解和發展,機器翻譯等研究中,分析語言主要的方法是基於規則,但對於用規則無法表達或不能涵蓋的語言事實,計算機就很難處理。語料庫出現之後,人們利用它對於自然語言進行調查與統計,建立統計語言模型,研究和應用基於統計的語言處理技術,在訊息檢索、文本輸入和整理語料的自動分詞和標注,到語料的統計和檢索,自然語言訊息處理的研究都為語料的加工提供了關鍵性的技術。
計算機語料庫的功能主要涉及三個層面,一是語料庫的規模,二是語料的分布,三是語料加工的程度。規模大小關係到統計數據是否可靠,語料的分布涉及統計結果的適用範圍,語料加工的深度則決定這個語料庫能為使用者提供什麼樣的語言學訊息。
語料加工主要指文本格式處理和文本描述兩項工作,文本格式處理是對於已採集的語料文本進行整理,轉成格式一致的電子文本,例如資料庫格式,XML格式等。文本描述是說明每一篇語料樣本的屬性或特徵,包括篇頭描述和篇體描述。篇頭描述說明整篇語料樣本的屬性,例如語體、內容所屬的領域、作者、出版時間、發行出版社…等,篇體描述是在文本裡添加各種語意學屬性標記,對於漢語語料庫來說,常見的有詞語切分標記、詞性標記、專有名詞標記,還有針對語法特徵標記,如子句標記或語意訊息標記…等。對於漢語語料庫的加工,一般是從詞性切分、詞性標記,到語法、語意屬性標記循序漸進。所標注的訊息增加,語料加工的深度也就相對的增加。
通常沒有篇體描述訊息的叫做生語料,對漢語的生語料只能以字為單位進行檢索與統計,而經過詞語切分處理的語料,就能夠以詞為單位進行檢索、統計和定量分析。如果還加注了詞性標記,那麼可以獲得的訊息就更多了。語料的標注如果由人來作,當然能夠保證其準確性,但是對於處理大規模的語料來說,顯然人工標注較為不切實際。因此每個大規模的語料庫加工往往需要藉助自動化的方式,其中詞語自動切分,詞性自動標注就成為眾所矚目的語料加工技術。
(二)操作實例— 台灣兒童語料庫數位化工作流程
「台灣兒童語料庫」(Taiwan Child Language Corpus,簡稱TAICORP)是將所收集之台灣兒童口語錄音語料,依照世界標準的兒童語料交換系統 Child Language Data Exchange System(簡稱 CHILDES, MacWhinney and Snow 1985, MacWhinney 1995)格式,建構成語料庫。其主要目的在(1)提供國內外學者語料共享的便利性與語料分析工具;(2)藉由標準規格的設定,使台灣兒童語料的收集能更有系統、更有效率,並且快速地涵蓋台灣地區所有語言,並設立相關網站,開放國內外學者使用。
在新生代普遍使用國語的時代背景之下,台灣閩南語兒童語言所學得的語料相較之下顯得彌足珍貴。此語料庫可提供語音學、音韻學、構詞學、句法學、語意學、語用學等不同層面的語言學與兒童語言習得研究,也可提供語音工程方面的研發與應用。本計畫由國立中正大學語言學研究所蔡素娟教授主持,從1997年10月開始錄音,經轉記、標記、格式化等過程,歷時將近九年。共收錄431人次錄音檔案,錄音總長共約330 小時。文字檔共約五十萬句,一百六十多萬詞。
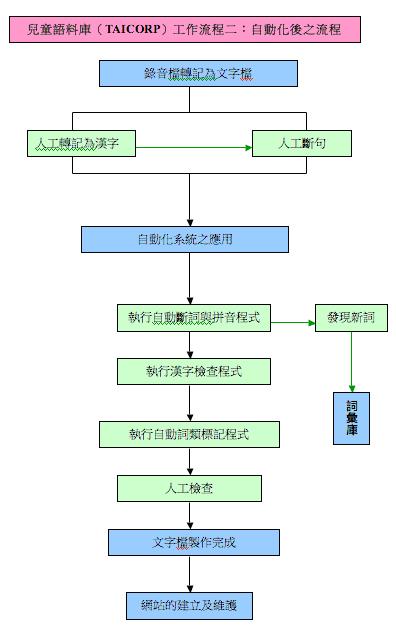
該計畫的數位化作業,大致依照下列五項步驟進行,依序分別為:一、錄音;二、錄音檔案轉記為文字檔;三、建立詞彙庫;、四、建立自動化系統;五、自動化系統之應用等五個方面,共細分二十三項步驟依序進行,分別介紹如下。
閩南語兒童語料數位化工作流程圖如下:
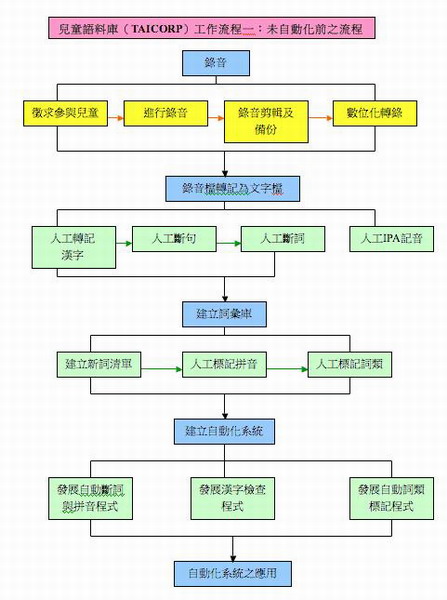
圖一:
(1) 錄音
「錄音」部分分為五個步驟進行,分別為「訓練研究助理」、「徵求參與兒童」、「進行錄音」、「錄音剪輯及備份」、「數位化轉錄」。
A. 訓練研究助理:由計畫主持人訓練研究助理。最核心的研究助理有三名。簡述如下:具備語言學碩士知識背景,並以閩南語為母語。透過每星期三到六小時的討論會,訓練助理,瞭解閩南語音韻及書寫系統、閩南語詞彙、句法、語意及詞類標記系統、CHILDES系統及兒童語言習得相關文獻;並熟悉IPA國際音標記音。
B. 徵求閩南語家庭之兒童:目標選定中正大學附設托兒所、幼稚園及鄰近鄉鎮,徵求來自以閩南語為母語之家庭,並年齡在一歲至三歲之間的幼兒。陸續選出共14名兒童。
(a) 以海報及網路發布廣告;利用幼稚園家長日到場對家長說明,徵求說閩南語家庭的兒童。
(b) 排定錄音時間:聯絡家長,並排定錄音時間表。
C. 進行錄音:
(a) 準備錄音器材:錄音器材選擇方便攜帶、機動性強、容量較大、易長期保存語料之錄音器材。下圖左起為迷你光碟片、專業用耳機、專業用麥克風、迷你光碟隨身錄音機。
(b) 進行錄音訪談:至兒童家中進行訪談錄音。錄音為週期性,寒暑假亦不間斷。二歲以下者,每週訪談一次;二至三歲者,每兩週訪談一次;三至四歲者,每二至三週訪談一次。每次訪談約1至2小時不等,實際錄音時間40至60分鐘。
(c) 錄音期間:1997年10月至2000年5月。共錄音431人次,約330小時。訪談方式為:錄下兒童在家長或保姆陪同下,在自己家中的日常對話。錄音的內容除了自然言說,還藉助圖畫簿、故事書、玩具、布偶、剪紙、摺紙或其他遊戲,引發兒童主動說話。
D. 錄音剪輯及備份
(a) 錄音剪輯:由助理將錄音光碟中不相關的錄音或太長的空白錄音刪除,將錄音切割為較小段落,在光碟中標記段落編號;於光碟中輸入錄音日期、檔名。每1小時的錄音約需耗時1.5小時剪輯。總工作時間:1.5*330小時=495小時。
(b) 錄音備份:使用迷你光碟錄音座及迷你光碟隨身錄音機進行迷你光碟備份製作。
E. 數位化轉錄:將迷你光碟錄音檔轉為較不佔空間之MP3格式,以方便儲存。於日後可隨時轉為語音分析所需之格式(如WAV格式)。所使用之轉錄軟體為GoldWave Digital Audio Editor(GoldWave Inc. 研發)。
(2)錄音檔轉記為文字檔
「轉記」分為四個步驟,依序為:「人工轉記漢字」、「人工斷句」、「人工斷詞」、「人工IPA記音」。
A. 人工轉記漢字:由於閩南語的漢字書寫系統目前並沒有定案,再加上有許多本字無法確定,或者有音無字的情形,因此有必要訂定文字轉記的原則。故在進行文字轉記前,首先需確立閩南語書寫系統,計畫所參考的辭典主要有四本,依優先順序排列為:《臺灣閩南語辭典》《台灣話大辭典》《廈門方言詞典》《閩南語詞彙》如下圖由左至右。轉記平台為CHILDES兒童語料交換系統。每1小時錄音需要花約10小時不等的時間轉記成文字檔。總工作時間:330*10=3,300小時。
B. 人工斷句:由於台灣兒童語料庫之語料為口語語料。助理需參考言談分析之斷句原則,將自然語言切分成個別獨立意義的句子。
C. 人工斷詞:由於目前無閩南語斷詞標準,故計畫根據中華民國計算語言學學會所訂定之「資訊處理用中文分詞規範調查研究及草案研擬」,將語句切分為獨立意義、且扮演特定語法功能的字串。
D. 人工IPA記音:採語音轉記 (phonetic transcription) 的方式詳細轉記兒童實際發音。在音段方面,以Unicode IPA符號記音,參考書目為Handbook of the International Phonetic Association (1999);聲調採用五度標音法。每小時的錄音約需花4.5小時記音。共4.5*330=1485小時。
(3)建立詞彙庫
錄音以人工轉記為文字需耗費相當大的人力,因此最終還是要建立自動化系統以降低人力,而系統的建立則需要詞彙庫作基礎。「建立詞彙庫」依序分為三個步驟進行:「建立新詞清單」、「人工標記拼音」、「人工標記詞類」。
A. 建立新詞清單:以轉記好之文字檔中之所有詞彙建立清單,經由人工確認詞彙清單中的漢字與詞典是否一致。
B. 人工標記拼音:根據教育部於民國八十七年所公佈之「閩南語羅馬拼音第二式」人工標記詞彙清單中的漢字之拼音。
C. 人工標記詞類:參考中央研究院詞庫小組「詞類標記原則」以及CANCORP: The Hong Kong Cantonese Child Language Corpus( Lee and Wong, 1998)、台灣閩南語動詞分類研究(曹逢甫, 1996) 等相關文獻。採用中研院詞庫小組的詞類標記,但是僅限於46個簡化標記,以避免詞類劃分過細時產生主觀強制性的歸類。
(4)建立自動化系統
「建立自動化系統」以上述詞彙庫為基礎。分為三個部分:「發展自動斷詞與拼音程式」、「發展漢字檢查程式」、「發展自動詞類標記程式」。
A. 發展自動斷詞與拼音程式:將輸入之句子或整個文字檔案,根據本計畫修訂「資訊處理用中文分詞規範調查研究及草案研擬」所撰寫之「閩南語斷詞原則」及詞彙庫之詞項,根據長詞優先之準則,與詞彙庫比較。若所輸入之漢字與詞彙庫一致,則以黑色呈現,並在其後標注拼音;若所輸入之漢字尚未建立於在詞彙庫,則以藍色呈現。此程式除了斷詞及標注拼音之外,還可以將新詞納入詞彙庫。
B. 發展漢字檢查程式:目的為求漢字與詞彙庫所列之標準之一致。搜尋之方式有三:一為輸入閩南語羅馬拼音、二為輸入可能之漢字、三為輸入國語之相對詞;透過此三種任一,皆能擷取出詞彙庫中含有該詞之詞條。但若該詞未建立於詞彙庫中,查詢後則不顯示。
C. 發展自動詞類標記程式:以人工標記詞類之文字檔作為基礎,發展自動詞類標記程式。將輸入之句子(已完成斷詞工作),自詞彙庫中擷取出其詞類標記;當該詞有多個詞類標記時,程式則以頻率最高之標記為優先考量並標記之。若該詞在詞彙庫中未標記詞類,則以三個問號(例:???)呈現。
(5)自動化系統之應用
A. 執行自動斷詞與拼音程式:將語句切割成詞,並標注拼音。
B. 執行漢字檢查程式:檢查漢字與詞彙庫所列之標準是否一致。
C. 執行自動詞類標記程式:標記詞類。
D. 人工檢查:檢查程式輸出檔,如欲標記的詞不只一個詞類,則檢查其自動標記是否正確。
(6)網站的建立及維護
網站架構及內容之編纂:計畫主持人與研究助理討論網站內容及所呈現之介面。
網站內容包含語料庫簡介、資料庫、使用手冊、相關程式以及相關網站之連結。
A. 網站之建立及維護:為語料庫建立專門網站,以供全球各地學者研究之用。完成最後檢測之後,網站則開放外界瀏覽。
〈目錄〉
 語料庫數位化工作流程指南 (324.6 KB, 4,182 hits)
語料庫數位化工作流程指南 (324.6 KB, 4,182 hits)
評分:
 (No Ratings Yet)
(No Ratings Yet)
