



























語料庫數位化工作流程指南
Tags: 指南, 數位化工作流程, 語料庫數位化, 語言學 發表: 2008-01-09, 點閱: 24,727 , 加入收藏櫃 , 列印
,
列印
,  轉寄
轉寄
想加入的書籤:














參、語料庫國內外比較與介紹
(一)國內—漢語平衡語料庫
「中央研究院現代漢語平衡語料庫」簡稱「研究院平衡語料庫」(Sinica Corpus ),是世界上第一個有完整詞類標記的漢語平衡語料庫。由於加詞類標記的漢語語料庫是史無前例的嚐試,這個語料庫是由中央研究院資訊所、語言所共同指導的詞庫小組完成的。該小組由陳克健(資訊所)、黃居仁(語言所) 兩位研究員主持,自1990年前後,便開始致力於中文語料庫的收集(Huang & Chen 1992),至1994年止已收集有近二千萬字之現代漢語語料及超過五百萬字之古代漢語語料(Huang 1994)。由於有了處理中文語料庫,及大量處理電子詞庫中詞條的經驗(陳克健等 1991, Chen 1994),中央研究院詞知識庫小組認為,應有足夠的實質與人力條件來進行耗時費力的漢語平衡語料庫建構。
因此,在1994年分別得到了中央研究院「中文資訊」跨所研究群之專案計畫及國科會計畫補助,乃開始著手進行現代漢語平衡語料庫的建構。為兼顧理想與實用性,初步目標定為兩百萬詞,為傳統小規模平衡語料庫之兩倍,1996年經計算中心設計規劃完成 WWW版,開放供各界使用,1997年開放的研究院語料庫3.0版已達到五百萬目詞的預計規模。2001年國家型數位典藏科技計畫展開,詞庫小組認為應持續收集近年之語料,使語料樣本能完整呈現二十世紀臺灣使用漢語的全貌,因此以新五百萬詞為目標進行知識典藏工作,目前介面已升級至4.0版,提供更完整的語料條件檢索功能。
(二)國外—British National Corpus
British National Corpus(以下簡稱BNC)為一英語平衡語料庫,廣泛收錄20世紀後半的文本與口語資料,其中文本約佔九成,包含全國與地方性的報紙、各種類別的期刊、學術論文、已出版或未出版之書信與手稿…等;口語部份約佔一成,包含大量非正式的日常對談、較正式的商業與政府會議、甚至於廣播節目與聽眾來電,日常對談的部份則徵求義工錄製而成,對談內容跨各年齡層、地區與階層。
以語料庫的類型來說,BNC為單語語料庫,收錄以現代英式英語為主之語料,而非歷史性之英語,內容方面則不設限,平衡並多元收錄各式不同語料。
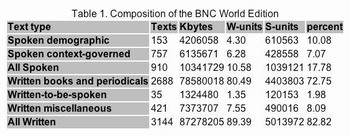
BNC是由產學界共同組成集團運作,產業界包括牛津大學出版、朗文出版(Addison-Wesley Longman) 、樂思出版(Larousse Kingfisher Chambers);學界則包括牛津大學計算中心(Oxford University Computing Services, 簡稱OUCS)、蘭卡斯大學計算語言中心(University Centre for Computer Corpus Research on Language, 簡稱UCREL)與大英圖書館研究與創新中心(British Library’s Research and Innovation Centre)。
語料庫建立須經過幾個關鍵步驟,由不同單位進行,並記錄每個階段,存於OUCS的資料庫,建立程序如下 :
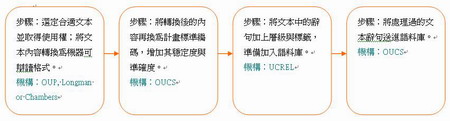
BNC於西元1991年開始建立,並於1994年建置完成,最初的版本於1995年二月發行,並提供歐洲學者研究使用。
目前BNC有各種不同的版本提供使用,但網站上依然開放大眾查詢,對於學術研究或是一般語言學習都相當的有幫助。
基本而言,不論是漢語平衡語料庫或是BNC,都是以平衡抽樣試圖表現當代語言的全貌,因此包含各種類別的文體,因此對於語言研究來說,是相當重要的參考樣本。以下也順帶介紹一些典型的平衡語料庫:
(1)布朗語料庫(Brown Corpus)
於六O年代由Francis與Kucera於布朗大學建立,是世界上第一個根據系統性原則採集樣本的標準語料庫,具一百萬詞規模。文本選自於1961年美國出版的美式英文普通語體,共15種題材,500個樣本,並每個樣本不少於2000詞,並於1964年完成。布朗大學並於1961年出版了當代英語詞頻辭典。約到七O年代,由Greene與Rubin設計了TAGGIT詞性標注系統,包含詞類標記81種,規則3300條,自動標注之準確率約77%。
(2)LLC口語語料庫(London-Lund Corpus of Spoken English, LLC)
由倫敦大學著名語言學家Randolph Quirk於1960年代建置之口語語料庫,包含2000小時之對話與廣播等口語素材,結合1975年 Jan Svartvik在Lund大學進行的 Survey of Spoken English (SSE),SSE於1981年完成,於是建置成 London-Lund Corpus of Spoken English。LLC其中有87個文本,每個文本約5000詞,最終規模為五十萬詞。所採集的口語語料主要分為五大類:面對面交談、電話交談、討論、採訪以及辯論;還有未經准許的公開評論、論證、演講;經准許的公開演講。
(3)朗文語料庫(Longman Corpus)
朗文語料委員會(Longman Corpus Commitee)建置,由1981年1月開始至1990年11月歷經九年多完成。語料選自19世紀末至20世紀初的英語語料,知識性文本(informative)佔60%,想像性文本(imaginative)佔40%,並廣泛橫跨十種領域,如:自然、純科學、應用科學、社會科學、國際事務…等,規模約2,800萬詞。
〈目錄〉
 語料庫數位化工作流程指南 (324.6 KB, 4,334 hits)
語料庫數位化工作流程指南 (324.6 KB, 4,334 hits)
評分:
 (No Ratings Yet)
(No Ratings Yet)
