



























漢籍全文數位化工作流程指南
Tags: none 發表: 2008-01-18, 點閱: 33,781 , 加入收藏櫃 , 列印
,
列印
,  轉寄
轉寄
想加入的書籤:














參、前置作業
無論欲進行數位化材料之數量多寡,或是計畫之規模大小,數位化都是一項所費不貲且耗時耗力的工作;因此,事前的籌劃評估與準備,不容小覷。
實際進行文字數位化工作之前的準備作業有兩項,第一為「選定材料」,此工作涉及對於既有材料之瞭解與整體目標之規劃,第二為「制訂作業規範」,有助整體作業之執行成效與品質管理。
一、選定材料
(一)數位化材料之選擇
根據數位化目的之不同,數位化材料之選擇標準亦各有異,加上每個計畫經費不一,且多有限,故選擇數位化材料時,應事先考量文物數位化之優先順序,使得人力經費之支出能達到最佳成效。文物數位化之優先順序【2】,可依照珍貴性、重要性、成本效益等程度,概分為以下六項:
1.典藏品的評等度,如國寶、重要古物等教育部標準、機密程度等等。
2.典藏品的珍貴度,例如文物具有獨創性、稀有性、時代價值、不可替代
性等因素。
3.典藏品的保存難易度,包括脆弱、無法複製拷貝、有消失之虞等考量。
4.數位化後之成本效益。
5.數位化後在研究、教育、經濟等能面的應用價值。
6.其他。
此外,版本的選擇在全文數位化工作裡,也佔有很大比例的關注與考量。當知識近入書寫時代,印刷術尚未發明之前,書籍多以人工抄錄的方式傳承接遞,故常有抄錯、漏抄之時,即使進入鉛字排版時代,還是會有會錯意、選錯字的情況發生;而且傳統中國頗為重視各類書寫文獻,不僅歷代君王,亦含文人雅士、學者志士,重視書籍文獻之考察與典藏,官修、私修之史書總集亦多,從三國時代的三史、十三代史到乾隆皇帝欽定之二十四史,可見史書典籍因年代版本不同有收錄、記載之差異,是協助研究學者進行分析研究之重要線索。此外,數位化的重製作業關係藏品與成品之著作權法,若能請求著作權授權,則可順利進行數位化;若無法取得,或可更換可以取得授權之版本,否則必須重新揀選材料。
(二)數位化材料清單之建立
選定即將進行數位化之書目後,應建立一份完整詳實的待輸入書目清單。因為數位化的物件為書籍,故以書目之最小集合單位冊或卷為列入清單的基本單位,一冊書即著錄一筆資料,每筆資料所記載的內容應包含以下出版資訊:
1.書名
2.作者名
3.出版地
4.出版社
5.出版年限
6.版本
除上述出版資訊外,亦須記載書目之數量,並且妥善保存此書目資訊(如表2),作為之後進行數位化工作之憑據。
表2、中央研究院歷史語言研究所漢籍全文資料庫待輸入書單

二、制定規範
為確保數位化前後環節銜接順暢,產出成果之品質穩定,需制定相關作業規則與檔案格式,以供遵循與評量。
大多數計畫或單位之規範制定,參考同業已訂立之標準,其他則來自自身經驗的累積,不過制定規範還是以滿足個別計畫之最終目標為最高準則,並非一字不漏、全部採用他人作法。雖然作業規範依計畫目標有所歧異,之間仍有些許共同原則,以下介紹各項數位化作業之工作規範與檔案規則參考。
(一)數位影像檔案規格
提供文字繕打輸入之底本有二種,一為掃描原書製成之數位影像,二為影印原書製作之複本。
掃描原書之圖檔,除可用於繕打輸入與校對用途,還可於之後資料庫建置時,將圖檔與相對應之電子全文連結,成為全文與影像資料庫。關於數位化影像之規格設定,數位典藏國家型科技計畫區隔數位化檔案規格為瀏覽級、商務級與典藏級三級:
1.典藏級圖檔:目的為永久典藏,影像品質不失真,詳實反映原件狀況。
2.商務級圖檔:目的為提供未來之加值應用,如出版、印刷、複製、交換或販售,影像品質須符合印刷之要求。
3.瀏覽級圖檔:目的為展示於網路上,影像品質須符合電腦螢幕瀏覽及網路傳輸之要求。
典藏級的影像解析度為人類眼睛鑑別影像最高值的300dpi,格式為適用不同軟體、平台,壓縮不失真,適合作為原始檔之TIFF檔。商務級的解析度同樣為300dpi,影像格式則是高效壓縮使得檔案變小之JPEG檔,容易造成影像細節流失。瀏覽級之影像解析度則為便利傳遞,再利用價值低之72dpi,影像格式為JPEG。三者的色彩模式則都為RGB(24bit/pixel)。(表3)
| 瀏覽級 |
商務級 | 典藏級 | |
|---|---|---|---|
| 檔案格式 | JPEG | JPEG |
TIFF
|
|
色彩模式
|
RGB(24bit/pixel) | RGB(24bit/pixel) |
RGB(24bit/pixel) |
|
解析度
|
72dpi | 300dpi | 300dpi |
有鑒於全文數位化之掃描圖檔可能使用於不同目的,故原始掃描圖檔應設為高階的典藏級,即300dpi的TIFF全彩檔,以便日後降階應用。
另外,也有單位使用影印的副本作為繕打輸入之底本,影印之影像大小則依據原書字體大小與清晰度,決定比例大小。
(二)數位檔案命名原則
一旦執行掃描,產生數位影像之後,便需一一替檔案個別命名,以便利數位資料之管理與檢索。
使用檔案命名字元時,為確保檔案名稱能夠符合不同作業平台之讀取格式,應注意一般檔案命名事項:
1.以小寫英文字母與數字做為檔案命名之編碼組合。
2.避免使用%、/、?、#、*、-等特殊字元。
除了一般性原則之外,亦需依照數位化物件之媒體類別與不同特性,額外增加能夠突顯物件特性之命名規則。掃描圖書典籍而產生之數位化影像,其檔案名稱包含三種層次,圖書代碼、冊卷號、頁碼。其中頁碼為檔名,副檔名為.tif。
例:aaaaaooozzzzzzzz.tif
aaaaa=圖書代碼;
ooo=冊次號;
zzzzzzzz=頁碼。
1.第一層:圖書代碼
長度不固定,計畫單位可自行設定,建議皆為數字。
2.第二層:冊卷號
長度固定為三碼,皆為數字。
3.第三層:頁碼
(1) 檔名長度共8bytes,依原書內容頁碼編頁。
例:第一頁 → 00000001.tif。
(2) 封面頁碼固定為c0000001.jpg,倘若為平裝書加工精裝者,以原平裝
書之封面為主。
(3) 原書內文頁碼第一頁前面與內文頁碼不連貫之各頁(即非正文部
份),如序、目次等,可於非正文部份起依序計數,並於頁碼第一位
加上英文小寫字母“a”以區別之,如:a0000001.tif,a0000002.tif…
(4) 內文後面多出且與內文頁碼不連貫之各頁,如附錄、圖表、參考資
料等,可於非正文部份起依序計數, 並於頁碼第一位加上英文小寫
字母“ b ” 以區別之, 如:b0000001.tif,b0000002.tif…
(5) 原文編有頁碼之空白頁或廣告頁,仍依原順序編碼掃入。
(6) 原文未編頁碼且為多餘之空白頁,則予以跳過不掃。
(7) 內文中之插頁,若未編頁碼,則以接續前頁之編碼後加“_”編入。如:在86 頁至87 頁間插頁2 頁但未編碼, 則以“ 000086_1.tif ”、“000086_2.tif”編號。
(8) 原文若分左、右版面頁碼者,左版頁碼需以小寫L區別,右版頁
以小寫R區別。如:頁左133→檔名為l0000l33.tif
頁右12→檔名為 r0000012.tif
(9) 正文若同時有兩組頁碼標示者,例如一組各章節從1編頁,一組為
總頁碼者,則掃描取該書冊目次所標示之頁碼為準【3】。
(三)人工輸入規則
執行人工輸入之前,必須建立輸入規則。除了內文的文字,本文以外之符號標誌、圖片、表格、夾注小字、段落、頁碼、欄位、校勘符號,以及空白字元、空白行、圖形、系統缺字……等,都需明確標示著錄格式,如:
1.頁碼、欄位:每欄開始都要以半形英數先輸入一行pxxxxn,xxxx為四位數,n為a(上欄)或b(中欄)或c(下欄)。
2.序及經卷名:行前不留白。
3.作者及譯者名:行前留四個全形空白。
4.正文:行前不留白。
5.正文夾註小字:以一組半形( )前後包括。
例  輸入為:十一月(二段)
輸入為:十一月(二段)
輸入為:十一月(二段)6.雙行夾註小字:同樣以一組半形( )前後夾住,需注意文字走向。
例  輸入成:望江南(三寶三段送佛一段)
輸入成:望江南(三寶三段送佛一段)
7.空行:隨文中空行。
8.空格:按書面空格輸入全形空白字元。
9.圈點:隨圈點處輸入「。」。
例  輸入為:身所居。二自受用土。自受
輸入為:身所居。二自受用土。自受
10.校勘符號:採兩位數半形阿拉伯數字與中括號
例  輸入為:相[01]把成陰陽。
輸入為:相[01]把成陰陽。
輸入為:相[01]把成陰陽。11.特殊符號:以相似全形符號表示。
例  各輸入成:有一○為千
各輸入成:有一○為千
各輸入成:有一○為千 ▲洪州黃
還。無□
12.圖形:以【圖】表示。
例  輸入為:【圖】第七末那識
輸入為:【圖】第七末那識
輸入為:【圖】第七末那識 轉平等性智
13.缺字:如果可以用組字式或構字式(下一小節將介紹)表示,即示之;若模糊或是難以表達之處,可統一暫以全形●表示【4】。
因為每種文獻的排版、書寫、或語法等書籍體例各有不同,應根據各書籍體例以及數位化目標,制定適合個別體例之人工輸入規範。不過大致上,關於全文輸入,還是有以下幾基本大原則:
1.依照書中原文輸入,內文不清楚處,不做模糊判斷,待專業人士進行判斷2.同原書換行位置折行。
3.由於古文書多無標點符號,輸入時只進行斷句,不加註新式標點符號。
(四)新增缺字系統
漢字發展過程裡,因為地域、時代或其他因素,衍生了一字多形(例如「眾」與「?」),無法窮舉之特色,所以現有的電腦交換碼一旦用來處理古籍或佛典、道藏等文獻,缺字問題即層出不窮。缺字的根本及務實的解決之道,應該在現有的編碼方法下,根據漢字的構形規則,針對這些為數眾多但又不常出現的漢字,提出一套有效的編碼方法【5】。
目前國內有兩種缺字組字標準,其一是最為廣泛使用的缺字系統──中央研究院研發之漢字構形資料庫【6】。漢字構形之基本構字單位稱作部件,也就是一個用來構造其它字的形體。如「日」、「京」是「景」的部件,「景」、「頁」是「顥」的部件,而「顥」是「灝」的部件。
部件還有層次,例如「顥」可拆分成「景」與「頁」,「景」又可拆分成「日」和「京」。漢字最常用的拆分方式為橫連( 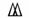 )、直連(
)、直連(  )與包含(
)與包含( ),因此,「顥」等於「景」 「頁」,「景」等於「日」 「京」,「圍」等於「囗」 「韋」。另外為了輸入方便,也造了一些方便符號,表示相同部件之排列方式,如兩個「克」橫連的「兢」等於「
),因此,「顥」等於「景」 「頁」,「景」等於「日」 「京」,「圍」等於「囗」 「韋」。另外為了輸入方便,也造了一些方便符號,表示相同部件之排列方式,如兩個「克」橫連的「兢」等於「 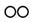 克」,兩個「戈」直連的「戔」等於「
克」,兩個「戈」直連的「戔」等於「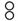 戈」,三個「車」呈三角形狀排列的「轟」等於「
戈」,三個「車」呈三角形狀排列的「轟」等於「 車」,四個「火」呈四角狀排列的「燚」=「
車」,四個「火」呈四角狀排列的「燚」=「 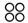 火」。而無從以構字式拆解之字形,則可使用從缺符號「
火」。而無從以構字式拆解之字形,則可使用從缺符號「  」表示(表4)。
」表示(表4)。
|
符號 類別 |
中文 意義 |
組字 符號 |
使用說明 |
範例 |
|---|---|---|---|---|
|
拆分 符號 |
橫連 |
|
當部件的排列順序由左至右 |
灝、順 |
|
直連 |
|
當部件的排列順序由上至下 |
含、義 |
|
|
包含 |
|
當部件的排列順序由外至內 |
圍、魁、連 |
|
|
方便 符號 |
|
|
二個相同部件直連 |
炎 |
|
|
|
三個相同部件直連 |
|
|
|
|
|
二個相同部件橫連 |
朋、沝、孖 |
|
|
|
|
三個相同部件橫連 |
|
|
|
|
|
三個相同部件呈三角狀排列 |
焱、聶、磊 |
|
|
|
|
四個相同部件橫連 |
|
|
|
|
|
四個相同部件直連 |
燚 |
|
|
|
|
四個相同部件成四角狀排列 |
|
|
|
其他 |
起始標示 |
|
當拆分有兩種以上時,代替拆分,包夾在所有部件之前面,以及最後 |
|
|
終止標示 |
|
|||
|
缺字標示 |
|
代替從缺的部件 |
|
其二為中華電子佛典協會在進行佛典的數位化工作時,以中央研究院之漢字構字式為底本,獨家研發出該單位特有之組字式規則。相較於中央研究院之漢字構字式以部件作為基本構形單位,中華電子佛典協會是以BIG5(大五碼)系統字作為組字之基本單位,故無造字問題,使用者無需另外安裝造字程式或圖檔,即可讀取組字式。
組字式採用數學裡的加減乘除四則運算符號來表示,共使用十個符號。這十個符號,其中七個──「*」、「/」、「@」、「-」、「+」、「(」、「)」,用來表示字的左右上下分合關係;問號「?」,表示某字無法用組字方式表示的部分;另外二個半形符號「[]與「」」,表示組字式的起迄【7】(表5)。
| 符號 |
說明
|
範例
|
|---|---|---|
| * |
表橫向連接
|
明=日*月
|
| / |
表縱向連接
|
音=立/日
|
| @ |
表包含
|
因=囗@大 或 閒=門@月
|
| - |
表去掉某部份
|
青=請-言
|
| -+ |
若前後配合,表示去掉某部份,
而改以另一部份代替 |
閒=間-日+月
|
| ? |
表字根特別,尚未找到足以表示者
|
背=(?*匕)/月
|
| () |
為運算分隔符號
|
繞=組-且+((土/(土*土))/兀)
|
| [] |
為文字分隔符號
|
羅[目*侯]羅母耶輸陀羅比丘尼
|
上述兩種組字規則,前者多為政府機關單位與中央研究院院內開發之資料庫所採用,是台灣發展最早之構形系統;後者則為中華電子佛典協會獨用,它簡化了漢字構形之複雜度,協助繕打人員輕鬆組織缺字。此外,政府也研發一套國家標準中文交換碼方案,並由行政院主計處電子處理資料中心建置「CNS11643中文標準交換碼全字庫」, 以解決個人電腦中文字數不足與自行造字問題,不過,除政府機關與戶政單位採用此系統外,一般民間乏人問津。
(五)通用標記語言
標記(Mark up),是在稿件或文章上加上的記號,以記錄各種不同的資訊。為避免自創造標記系統影響資料交換之互通性,國際間很早就開始建立通用的國際標準。西元1986年,發明了最早的標記語言SGML(Standard Generalized Markup Language,標準通用標記語言),它定義了如何描述一組標記標籤(tag)的規則,但由於它相當的複雜,因此應用並不十分普遍。其次是紅遍半邊天的HTML(Hypertext Markup Language,超文字標記語言),HTML是SGML的一種應用,以其簡單易用的語法隨著網際網路的興起而盛行,世界各地不同語言、文化、電腦作業平台之間,得以藉由HTML這個標準的共通語言相互溝通,地球村的資訊交流達到前所未有的迅速與廣度。
然而HTML的缺點─正是它的優點─也漸漸的浮現,HTML不再能滿足網際網路上許多新興的需求。SGML夠強卻太複雜,HTML夠簡單卻不夠強大,於是標記語言的專家又為設計了一套既強大、又不太難、且適用於網際網路的標記語言─XML(eXtensible Markup Language,可延伸性標示語言)。
然而HTML的缺點─正是它的優點─也漸漸的浮現,HTML不再能滿足網際網路上許多新興的需求。SGML夠強卻太複雜,HTML夠簡單卻不夠強大,於是標記語言的專家又為設計了一套既強大、又不太難、且適用於網際網路的標記語言─XML(eXtensible Markup Language,可延伸性標示語言)。
標記主要可應用於兩類,一類是關於「排版或顯示格式」的標記,另一類則是關於「資料結構或內容」的標記。例如最為大眾熟悉之標記語言HTML(HyperText Markup Language),可能會有如下的用法:
佛教資料電子化技術探討-以< b >中華電子佛典協會< /b >為例。
佛教資料電子化技術探討-以< b >中華電子佛典協會< /b >為例。
在這裡,< b >……< /b >表示「中華電子佛典協會」這些字要加粗體字(bold)顯示,這是第一類關於「格式」的標記。而關於「內容」的標記,可能為如下用法:
史記
< byline type="Author">司馬遷< /byline >
史記
< byline type="Author">司馬遷< /byline >
這裡的< byline >……</ byline >標出史記之作者(author)馬遷。這種將「顯示格式」與「內容」分離的做法,能讓電腦「看懂」經文【8】。
有了共同的標記語言XML,標記格式如出一轍,可用同樣的標記語言、標記格式來定義各自不同的標籤名稱,例如要標出一個段落,可以有如下數種不同的標法:
1.< p >……< /p >
2.< para >……< /para >
3.< 段落 >……< /段落 >
這些都是符合XML標準的標記,但在資訊交換上將會造成問題,需要增加一道標記轉換的手續。如果能有共同且統一規格之標籤名稱,這個問題就可以解決。
除此之外,早在SGML時代就有一個TEI(Text Encoding Initiative,文件符碼化)專案,研究各種不同西方文獻,整理出一套標籤集(Tag Set),希望獲得各方採用而促進電子文獻的分享交流。由於TEI的標籤集是根據文獻所歸納制訂,與SGML、HTML、或是XML相比,忠實反應了文獻的內容與架構,例如完整書目資訊、文獻及其來源之關係和版本、使用語言等,都有特定之標籤,足以滿足文獻標記之需求。本文將於第伍章──後設資料建置,概述TEI之基本介紹與操作守則。 (目錄)
註2:陳秀華,《書畫數位化工作流程指南》,2005年,http://content.teldap.tw/main/doc_detail.php?doc_id=548,頁4-5。
註3:數位典藏國家型科技計畫,10-4 地方文獻影像編碼原則,《技術彙編》,2004年。
註4:中華電子佛典協會,〈續藏輸入規則及範例〉、〈大正藏內文格式〉。
註5:莊德明,〈漢字缺字處理與梵巴藏字母的輸入〉,《佛教圖書館館訊》,第十四期, 1998年6月。
註6:數位典藏國家型科技計畫,〈第三部份第二章漢字部件及組字規則〉,《技術彙編》,2002年。
註7: 中華電子佛典協會,http://www.cbeta.org/data-format/rare-rule.htm。
註8:周邦信,〈標記語言的應用〉,《佛教圖書館館訊》,第二十四期,2000年12月。
註2:陳秀華,《書畫數位化工作流程指南》,2005年,http://content.teldap.tw/main/doc_detail.php?doc_id=548,頁4-5。
註3:數位典藏國家型科技計畫,10-4 地方文獻影像編碼原則,《技術彙編》,2004年。
註4:中華電子佛典協會,〈續藏輸入規則及範例〉、〈大正藏內文格式〉。
註5:莊德明,〈漢字缺字處理與梵巴藏字母的輸入〉,《佛教圖書館館訊》,第十四期, 1998年6月。
註6:數位典藏國家型科技計畫,〈第三部份第二章漢字部件及組字規則〉,《技術彙編》,2002年。
註7: 中華電子佛典協會,http://www.cbeta.org/data-format/rare-rule.htm。
註8:周邦信,〈標記語言的應用〉,《佛教圖書館館訊》,第二十四期,2000年12月。
 漢籍全文數位化工作流程指南 (2.3 MB, 1,930 hits)
漢籍全文數位化工作流程指南 (2.3 MB, 1,930 hits)
評分:
 (No Ratings Yet)
(No Ratings Yet)
