



























漢籍全文數位化工作流程指南
Tags: none 發表: 2008-01-18, 點閱: 33,782 , 加入收藏櫃 , 列印
,
列印
,  轉寄
轉寄
想加入的書籤:














肆、數位化物件程序
數位化物件程序指的是書籍在進行數位化過程中的掃描、輸入、與校對工作,此三項作業可以說是全文數位化的主要骨幹,也可以是最底層的基礎。事實上,書籍經過掃描、全文輸入與校對後,已經可以算是數位化過了,只不過只有經過此三項作業所產出之電子全文尚屬生料,若想增加日後之應用層面與研究價值,則需再進入後續之標記作業。
一、掃描
原書圖像之掃描之工作,視數位化藏品數量、計畫經費以及成本效益等考量,可選擇自行購買掃描器自製圖像,或是委託外部掃描廠商承包處理。若選擇自行掃描,可購買具備「自動送紙功能」與「自動編號存檔」之掃描器,節省人力。圖書掃描之作業流程【9】如下:
原書圖像之掃描之工作,視數位化藏品數量、計畫經費以及成本效益等考量,可選擇自行購買掃描器自製圖像,或是委託外部掃描廠商承包處理。若選擇自行掃描,可購買具備「自動送紙功能」與「自動編號存檔」之掃描器,節省人力。圖書掃描之作業流程【9】如下:
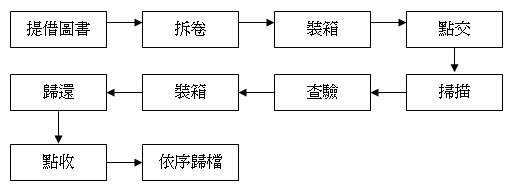
(一)提借圖書
根據書單,提調所選定之書籍,以提供單位內掃描人員或得標廠商影印及掃描。
(二)拆卷
將原書或原書影本拆卷,裁切騎縫邊,以備送掃。
(三)裝箱
將散裝書籍置入紙箱,並標示書名冊卷號,以資識別。
(四)點交
掃描人員或廠商所屬工作人員提卷,點驗書籍冊、卷名稱與數量正確無誤後,於簽收簿(表6)上簽名,始得提領。
| 書名 | 册數 | 提卷日期 | 提卷人簽名 |
|
點收人簽名
|
備註
|
|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
(五)掃描
1. 掃描之作業流程
(1) 掃描;
(2) 抽樣查看掃描品質—─有無線條或歪斜不清者;
(3) 掃描完畢後,檢查有無漏頁;
(4) 按照檔案命名原則編入檔名;
(5) 抽樣檢查頁數正確與否;
(6) 轉檔;
(7) 燒錄;
(8) 燒錄完成後,瀏覽檔案,若有缺漏或無法開啟的檔,加以修改或
補齊;
(9) 歸檔;
(10) 清潔掃描器。
2. 掃描之注意事項
(1) 掃描時應按册或按卷掃描,同一册(卷)由同一人處理為原則,一卷完全掃描完畢,始得進行下一册(卷),嚴禁不同册(卷)交疊掃描建檔,或同一册卷由二人以上分開處理。
(2) 掃描產生之圖檔需先設為高階影像,即300dpi的TIFF全彩檔。
而交付人工輸入之圖檔,可以再降階轉成TIFF-g4黑白格式,畫質
清晰且檔案又小。
(六)查驗
影像檔掃描建檔後應建立檔案清單,顯示檔案名稱、大小、筆數等資
料,提供品質及數量檢驗。
(七)裝箱、點收、歸還提借圖書
掃描人員或廠商所屬工作人員歸還書籍時,應恢復點交時狀況予以點
收,整理順序後歸檔。
二、輸入
文字的輸入方法有兩種,包括傳統的人工輸入法,以及運用軟體的OCR(Optical Character Recognition,光學文字辨識系統)辨識法。比較省時省力的方式是採用OCR圖檔辨識,此系統能夠自動分析圖檔上的文字並轉為純文字檔,但是目前的光學辨識系統仍處於辨識鉛字印刷文字之階段,尚無法精確辨識古籍經典中手之抄本或是雕版文字。因此,無法以OCR辨識之圖書文獻,則交付傳統的人工輸入,一字一句繕打處理,這種輸入法也是目前國內全文數位化單位最常採用的方式。
此外,還有一種製作文字檔的方式,就是收集網路上的現成電子檔,再加以修改格式成為符合單位所需文字檔。通常文史或宗教類的經典才可能有現成的電子檔,尤以佛經為最,據傳民間流傳抄寫佛經能夠累積功德,因而有許多信徒自發地在網路上公布其繕打之電子經文,一方面替自己累積功德,另一方面對於佛法的宣揚有所幫助。目前,僅有製作佛經數位化的中華電子佛典協會,從網路收集不少對於佛法或是佛典有興趣人士所自製的電子經文,作為校對的參照。以下,將分別介紹人工輸入與OCR光學文字辨識系統之作業辦法與須知。
(一)人工輸入
由於人工輸入必須依照原文一字不漏地輸入成電子檔,是費時耗力的大工程,除非預定進行數位化的圖書數量非常少,計畫內人力可以自行應付,否則絕大多數全文數位化單位會將此項作業委外製作,即使在人力成本不斷上揚的今日,委外人工輸入的作法還是全文數位化單位精簡勞務的最佳選擇。
中文人工輸入方面,亞洲這裡除了台灣之外,與台灣較近的市場還有中國大陸以及印度。台灣的人工打字市場,素質頗高,與其溝通協調較具成效,但唯一美中不足的是費用亦高;中國大陸的打字市場,人工打字成本較低,但是素質參差有別,溝通協調可能繁複,或者需要完整的職前訓練;而印度市場人力成本低,素質又高,在全球數位化浪潮之下,印度已成為世界全文輸入的最大基地,只不過礙於輸入語言以西方語系或梵語等的限制,依舊令國內數位化單位卻步。因此,國內大部分的全文數位化計畫,多半還是選擇於國內市場交易,選擇一配合優良的廠商,長期合作下去。
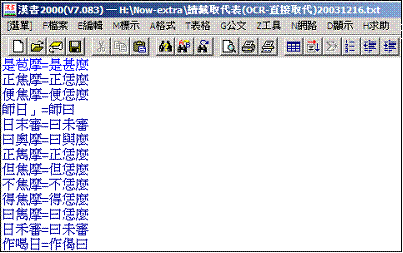
輸入時,應以掃描圖檔或影本為底本,確實遵循先前所制訂之輸入原則輸入。使用的軟體不限,任何能夠進行編碼之文書處理的軟體,如EmEditor、漢書98、或是Windows內建的記事本皆可。但是繕打之後產生之文字檔案,最好是純文字檔,並且依卷册號順序命名檔案名稱,以便後續利用時,不受格式之干擾與限制。
以中華佛子佛典協會佛典的人工輸入作業為例,該計畫以漢書2000作為輸入軟體,而且,為保留佛教經文之排版特色,以及提供正確的引用註解資訊,格外要求每筆文字輸入除了內文以外,還需仔細記載文字於文內所處之頁數、欄位(下圖一,左上pooo1a表示第一頁第一欄)、行數等資訊。
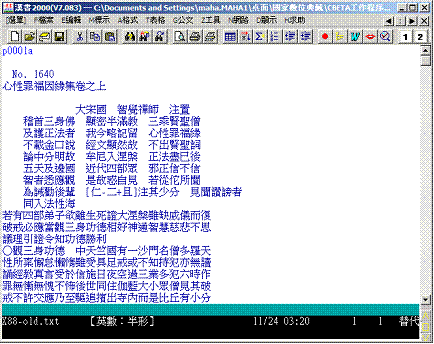
圖一、中華電子佛典協會佛教經文委外人工輸入產出之電子檔
(二)OCR光學文字辨識系統
OCR(Optical Character Recognition,光學文字辨識系統),是利用掃描器或數位相機等光學輸入設備,獲取印刷文件或手寫於紙上的文字圖片資訊,再以各種模式識別演算法逐一辨識分析文字型態特徵,轉換成電腦可操作的文字編輯,例如美國資訊交換標準碼(American National Standard Code for Information Interchange,簡稱ASCII code)或是BIG5(大五碼),進而轉入資料庫供使用者檢索。
以OCR光學辨識而言,中文字的辨識難度遠高於歐美國家的拼音文字。因為中文字的字數多,且字形架構與字形變化均有其複雜度,故國內的中文OCR研究直到最近才邁入實用階段。目前OCR的技術開發與研究,在台灣有丹青中英日文文件辨識系統、蒙恬認識王專業系統、全景軟體,在中國大陸則以清華文通和北京漢王最為著名【10】。關於各種OCR系統之介紹比較,本計畫於西元2005年出版之《報紙期刊全文輸入工作流程指南》(http://content.teldap.tw/main/doc_detail.php?doc_id=553)有詳細的討論與比較,本文不再贅述。
光學辨識易受圖檔清晰程度,影響文字分析結果,故在進行光學辨識前後,有些事前準備與事後修正需特別注意:
1.降階轉檔
因為內文與底色反差較大的圖檔較利於OCR光學辨識,因此在進行光學
辨識之前,必須先將全彩的圖檔轉成黑白或是灰階,抽離多餘的色彩干擾,有助辨識的正確度。
2.去除雜點
有些書籍之原文本身有非文字之讀音符號或注釋標記(圖二行間打勾與畫橫槓處),需以影像處理程式去除雜點,再生一個新的清晰圖檔,才能匯入OCR進行光學辨識。
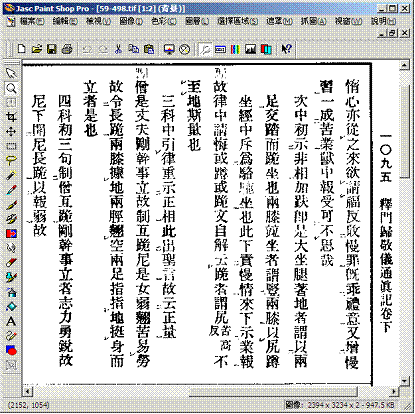
圖二、中華電子佛典協會含讀音符號與雜點之原始掃描圖檔
3.匯入OCR光學辨識系統
將降轉圖檔匯入選用之光學辨識系統(圖三、圖四),執行文字辨識功能,產生純文字檔。
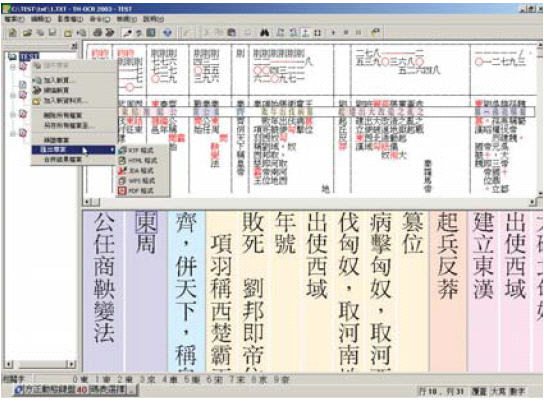
圖三、清華辨識系統介面
圖四、丹青辨識系統介面
4.字串取代
由於中文字形繁複,相似字形繁多,OCR無法百分之百分析出正確的內文字形,也會出現錯字。根據錯字出現的前後文,能夠判斷其正確用字,若能再依此整理出一份常錯字串表(圖五),便能以此正確字串快速批次取代OCR之常錯字串,減輕逐字校對之不便,並且提升OCR產生之文字檔的文字精確度約至90%。
圖五、中華電子佛典協會常錯字串取代表
三、校對
根據研究與統計,人工打字每人每天約可產出四萬八千字,一般錯誤率為千分之四至千分之五,換言之,人工輸入的正確率約為96%;而OCR光學文字辨識系統,依原文清晰度程度,正確率從90%(內文含有較多符號、異體字、缺字的古籍)到96%(鉛字印刷工整的近代圖書)不等。由於文字的正確率關係數位化成品之品質,錯誤率盡可能降得越低越好。目前全文數位化單位多將錯誤率的目標訂為萬分之一,也就是每一萬字只允許出現一個錯字,而達成此理想狀況的唯一方法就是投入心力校對。
現有校對的主要方案是人工校對,而義工校對與檔案比對則是拜網路、科技之賜而新起的發明與工具。將人工校對與後起的校對方案互相搭配執行,可以改善、提升文字的正確率,進而產出更接近原文的高品質電子全文。
然而,提升文字的正確率並非僅止於輸入錯誤的字,中國文字變異以及電腦系統缺字引發之各種缺字、異體字、避諱字等問題,都會於校對過程裡一一浮現,因而關於缺字、異體字與避諱字的解決方法,也是此章節的重點之一。
(一)人工校對
1.一校
逐字逐頁的人工校對是最為傳統的方案,雖然人力成本、時間、經費的支出都高,但是技術門檻最低,仍為多數單位執行校對的首選。
通常進行第一次校對的人員為廠商或是計畫裡負責輸入的人員,輸入完成即進行逐字校對並即時訂正。
2.二校
一校文字檔送回後,計畫人員應立即執行第二次校對。二校的工作方式有別於一校,是以隨機抽樣方式查驗,若達到合格要求,即燒製光碟進行備份;未達要求者則退回廠商或掃描人員處進行修改,並安排二次查驗。目前國內之全文數位化單位,多以錯誤率於萬分之一以下為最終目標。
(二)義工校對
因為某些數位化的文本具有特殊的傳播性質,或是計畫單位在執行、推廣數位化工作時佔有特殊優勢,動用大規模無償人力的校對志工團,應運而生。前者如中華電子佛典協會,受益於佛教教義有謂抄寫或讀誦佛經有助累積功德之文本特性,因而衍生出「網路校對」機制,即於網路上徵集志工約九百人,投入一人一頁分工的線上校對工作,其程序為:
1.上該單位網站(http://www.cbeta.org/index.htm)申請登記。
2.提領經文之純文字檔與圖檔。
3.利用看圖校對程式對純文字檔進行逐字校對。
4.校對完畢即可回傳。
後者為北京的一個全文數位化計畫,由上行單位直接向下發函分派多所大學之相關領域的教授進行點校。募集大量學者協助數位化工作,一方面可加速工作效率,另一方面也強化數位化成品的品質。
至於義工校對的成效為何?根據中華電子佛典協會的統計,一般透過OCR辨識產生的佛典文字檔,正確率只有90%,但經過網路義工校對之後,正確率可達98%。
(三)檔案比對
傳統人工校對,即使四校或十校等重複校驗,還是可能有未發現的漏網錯字。有鑑於此,中華電子佛典協會自行設計了檔案比對程式(如圖),即將相同內容但輸入方式不同(例如人工輸入和OCR光學文字辨識)的兩個文字檔,匯入此程式檔案,交由其依照字形、文字編碼對應出兩者的差異處,並予以另存成一個紀錄差異的檔案,節省人工校對必須逐字尋錯的時間,校對人員可直接針對錯誤之處再行查驗訂正。其他計畫單位若欲參照檔案比對之校對方式,或可委請資訊部門協助設計類似程式,以便加快校對速率。
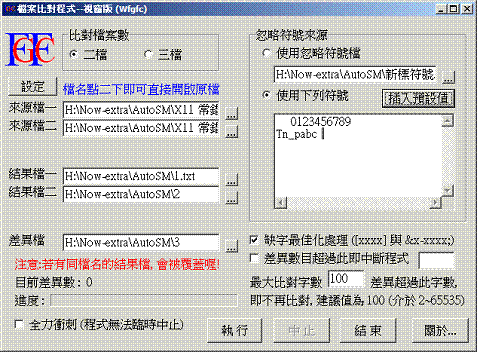
圖六、中華電子佛典協會檔案比對程式畫面
(四)異體字處理程序
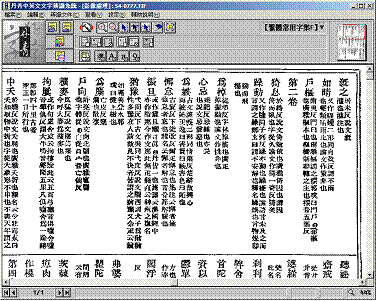
異體字是讀音、意義與正體字相同,但寫法不同的漢字,例如「體」的異體字,從教育部異體字字典(http://140.111.1.40/)查詢,可查出「体」、「軆」、「骵」、「躰」……等字(圖七)。異體字的形成時間、區域和原因不盡相同,但在很多的應用底下,異體字應該被視為相同的字。不過部份異體字的使用與上下文內容有關,因此異體字處理相當困難【11】。

圖七、教育部異體字字典畫面
雖然異體字判讀不易,難取捨,不過現在全文數位化單位多還是以「保留原文」的原則進行輸入。異體字的處理原則,以製作漢籍電子文獻資料庫著名的中央研究院漢籍工作室,他們對於異體字的處理辦法為:
1.若遇意義、用法相當等同於其正體字的純異體字,則輸入的時候以其正體字表示。
2.若判讀前後文仍無法確認異體字之義與用是否合於正字,則保留原文樣式示之。
3.還有一些異寫字,也就是音、義、用完全相同,與異體字間的差異主要是部件的異寫的字,如「 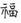 」與「福」皆由部件「示」構成,只不過「示」在「福」中異寫成「
」與「福」皆由部件「示」構成,只不過「示」在「福」中異寫成「  」。因為使用者瀏覽的方便性考量,只需找一個通用的參考字形輸入,另外再標示部件的異寫現象即可。但若無法判讀異寫字的用意,則同樣用保留原書字形。
」。因為使用者瀏覽的方便性考量,只需找一個通用的參考字形輸入,另外再標示部件的異寫現象即可。但若無法判讀異寫字的用意,則同樣用保留原書字形。
(五)缺字處理程序
台灣早期的全文數位化計畫多採用BIG5(大五碼),因為當時國際通用的編碼在漢字的編輯上不甚完備,國人因而自造編碼系統彌補缺字,但自從字集更為強大的Unicode(標準萬國碼)出現之後,不僅新的計畫直接採用Unicode,歷史悠久的常設單位也循序將原先的BIG5轉換為Unicode,而其中有些在BIG5裡依然無法顯示的缺字為Unicode編入,缺字數量較為減少。
國內對於缺字的處理對策,普遍為從早期沿用至今的「缺字即造字」原則,即 輸入時發現未列於Unicode的漢字,則交予中央研究院專責處理電腦缺字的文獻實驗室,由其漢字構形資料庫進行造字,產出字形圖檔,並以自立的編碼模式予以編碼,參考流程【12】如下:
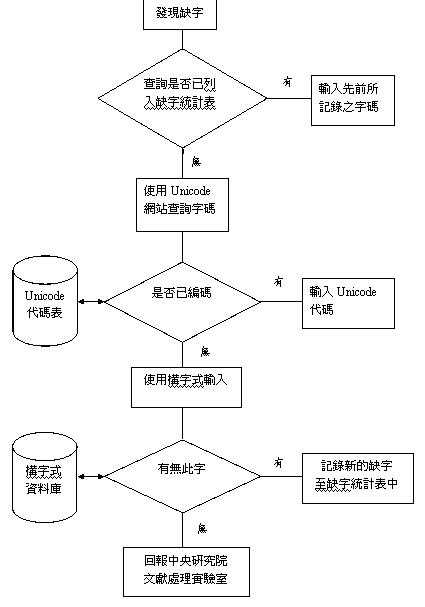
於Unicode網站(http://www.unicode.org/charts/unihanrsindex.html)查詢缺字(圖八),先以部首筆畫進入,之後再以扣除部首之外的筆畫查詢,即可找出所遇缺字是否已編入Unicode。而有關中央研究院資訊科學研究所文獻處理實驗室研發之漢字構形資料庫的相關介紹與使用說明,可上其網站(http://www.sinica.edu.tw/~cdp/)瀏覽、下載。
圖八、Unihan資料庫
使用漢字構形資料庫造字,它會將缺字新增成一個圖檔於全文中顯現,可以即時緩解電腦缺字問題;但是瀏覽端必須安裝造字程式始能閱讀圖像,而且只要處理古籍,缺字必定層出不窮,加上造字管理不易,實非治本之計。
現在全文數位化處理缺字問題的態度,趨向不再自行自行造字,也不等待Unicode新編缺字,而是改從標記著手,也就是在內文缺字出現處,以標籤與文字描述該缺字的之用與義,再以某種可以純文字表示之組字或者構字方式組合標示其形。如此一來,可節省造字工時,使用者可輕鬆閱覽,研究者更可循標記得到有關該缺字的原始與詮釋資訊。
(六)套用新式標點
我們現在所使用的新式標點符號,是民國初年五四運動之後,胡適與馬裕藻等人以古代舊式標點符號(句讀號)為基礎,並吸收西方標點符號所制定的;在此之前,漢文古籍多只以句、讀(。與、)表達語氣的停頓與終了,其餘的疑問、驚嘆語氣無從標明,後人重拾讀本,時常只能望文興嘆,不得其義。
因此,全文數位化除了參照原文依樣畫葫蘆,製作出相同的電子全文外,亦可於電子全文上標示新式標點,協助讀者以熟悉的斷句、語氣來解讀該本,增加資料之研究與傳播的價值。
唯此工作需動用中文句讀相關的學者、研究人員,針對個別文獻深入分析後標以新式標點,並於其後校對,耗費大量人力與時間成本。
文獻處理至此,在經過電腦輸入、校對、以及異體字、缺字等處理過後,已稱得上是一份完整的電子全文,而大部分單位的全文數位化工作,也僅止於此。但是在這強調數位化、資源流通、加值應用的時代,僅止於輸入、校對的電子全文不僅無法滿足應用加值的需求,還因輸入與校對的方法各異,不易互享資料,形成資源浪費。為了達成資源共享,知識流通,並促進學識研究,電子全文因於校對完成之後,再行以符合國際標準的標記語言進行標誌作業,以提升其研究、應用與分享之價值。
現有通用全球且適用於全文的國際標記語言,為專為博物館、圖書館之語文資料設計的TEI(Text Encoding Initiative),因其標誌範圍涵蓋結構面與內容面,又有一個類似圖書版權頁的標頭能夠概述資料,也是一種用來詮釋資料的後設資料,因此本文將標記列入後設資料工作範疇內,有關後設資料之著錄與應用,則於下一章節介紹。 (目錄)
註9:數位典藏國家型科技計畫,〈1-9檔案數位化影像製作文件處理工作場所規範:以外交檔案為例〉,《技術彙編》,2002年。
註10:程婉如,《報紙期刊全文輸入數位化工作流程指南》,2005年,頁18-20。
註11:袁國華,〈建立UNICODE漢字異體字表與異體字辭典相關研究〉,《國家數位典藏通訊》,第三卷第八期,2004年。
註12:國史館台灣文獻館難字處理程序。
 漢籍全文數位化工作流程指南 (2.3 MB, 1,930 hits)
漢籍全文數位化工作流程指南 (2.3 MB, 1,930 hits)
評分:
 (No Ratings Yet)
(No Ratings Yet)
