Posted By Ldudu0125 On 一月 18, 2008 @ 1:11 pm In 數位化書籍 | No Comments

國科會數位典藏國家型科技計畫自西元2002年起,便致力推動國內各項文物、資產的數位化工作,整合台灣漢字全文數位化的「漢籍全文主題小組」也於西元2005年7月成立。計畫成員有中華佛學研究所「佛典數位典藏內容開發之研究與建構─經錄與經文內容標記與知識架構」計畫,主題小組召集人由中華佛學研究所圖書資訊館館長─杜正民先生擔任,積極推動國內全文數位化相關計畫、單位的研究分享與技術切磋,其中,對於全文標記的推廣更是不遺餘力,因為合適生存於數位時代的數位資訊,必須具備優良成品、加值應用價值高,且能分享流通於世界之特性,故「全文標記」也是本文之撰寫重心。
本「漢籍全文數位化工作流程指南」,係紀錄彙整已執行漢籍全文數位化計畫、單位之工作經驗,參考國內外相關技術、標準,歸納統整一套電子全文數位化之工作流程,期能提供執行中單位之管理者與實際作業人員觀摩、檢視,且讓後續更多文書收藏單位加入數位典藏時,能依此參考依據,更有效的執行數位化工作。
|
目 錄
|
當火焰燃燒到達華氏451度,所有記錄人類智慧的典籍都將灰飛煙滅,但卻燒不毀被壓抑的靈魂……這是一個沒有火災的世界,消防員的工作,是縱火。這是一個所有的書都是「禁書」的世界,消防員的職責,是「焚書」。
註1:黃鴻珠,〈「觀前顧後」資料電子化的要訣之一〉,《佛教圖書館館訊》,第十五期1998年9月。
一、選定材料
(一)數位化材料之選擇

二、制定規範
| 瀏覽級 |
商務級 | 典藏級 | |
|---|---|---|---|
| 檔案格式 | JPEG | JPEG |
TIFF
|
|
色彩模式
|
RGB(24bit/pixel) | RGB(24bit/pixel) |
RGB(24bit/pixel) |
|
解析度
|
72dpi | 300dpi | 300dpi |
 輸入為:十一月(二段)
輸入為:十一月(二段) 例  輸入成:望江南(三寶三段送佛一段)
輸入成:望江南(三寶三段送佛一段)
 輸入為:相[01]把成陰陽。
輸入為:相[01]把成陰陽。 各輸入成:有一○為千
各輸入成:有一○為千 輸入為:【圖】第七末那識
輸入為:【圖】第七末那識|
符號 類別 |
中文 意義 |
組字 符號 |
使用說明 |
範例 |
|---|---|---|---|---|
|
拆分 符號 |
橫連 |
|
當部件的排列順序由左至右 |
灝、順 |
|
直連 |
|
當部件的排列順序由上至下 |
含、義 |
|
|
包含 |
|
當部件的排列順序由外至內 |
圍、魁、連 |
|
|
方便 符號 |
|
|
二個相同部件直連 |
炎 |
|
|
|
三個相同部件直連 |
|
|
|
|
|
二個相同部件橫連 |
朋、沝、孖 |
|
|
|
|
三個相同部件橫連 |
|
|
|
|
|
三個相同部件呈三角狀排列 |
焱、聶、磊 |
|
|
|
|
四個相同部件橫連 |
|
|
|
|
|
四個相同部件直連 |
燚 |
|
|
|
|
四個相同部件成四角狀排列 |
|
|
|
其他 |
起始標示 |
|
當拆分有兩種以上時,代替拆分,包夾在所有部件之前面,以及最後 |
|
|
終止標示 |
|
|||
|
缺字標示 |
|
代替從缺的部件 |
|


| 符號 |
說明
|
範例
|
|---|---|---|
| * |
表橫向連接
|
明=日*月
|
| / |
表縱向連接
|
音=立/日
|
| @ |
表包含
|
因=囗@大 或 閒=門@月
|
| - |
表去掉某部份
|
青=請-言
|
| -+ |
若前後配合,表示去掉某部份,
而改以另一部份代替 |
閒=間-日+月
|
| ? |
表字根特別,尚未找到足以表示者
|
背=(?*匕)/月
|
| () |
為運算分隔符號
|
繞=組-且+((土/(土*土))/兀)
|
| [] |
為文字分隔符號
|
羅[目*侯]羅母耶輸陀羅比丘尼
|
然而HTML的缺點─正是它的優點─也漸漸的浮現,HTML不再能滿足網際網路上許多新興的需求。SGML夠強卻太複雜,HTML夠簡單卻不夠強大,於是標記語言的專家又為設計了一套既強大、又不太難、且適用於網際網路的標記語言─XML(eXtensible Markup Language,可延伸性標示語言)。
佛教資料電子化技術探討-以< b >中華電子佛典協會< /b >為例。
史記
< byline type="Author">司馬遷< /byline >
3.< 段落 >……< /段落 >
這些都是符合XML標準的標記,但在資訊交換上將會造成問題,需要增加一道標記轉換的手續。如果能有共同且統一規格之標籤名稱,這個問題就可以解決。
註2:陳秀華,《書畫數位化工作流程指南》,2005年,[14] http://content.teldap.tw/main/doc_detail.php?doc_id=548,頁4-5。
註3:數位典藏國家型科技計畫,10-4 地方文獻影像編碼原則,《技術彙編》,2004年。
註4:中華電子佛典協會,〈續藏輸入規則及範例〉、〈大正藏內文格式〉。
註5:莊德明,〈漢字缺字處理與梵巴藏字母的輸入〉,《佛教圖書館館訊》,第十四期, 1998年6月。
註6:數位典藏國家型科技計畫,〈第三部份第二章漢字部件及組字規則〉,《技術彙編》,2002年。
註7: 中華電子佛典協會,[15] http://www.cbeta.org/data-format/rare-rule.htm。
註8:周邦信,〈標記語言的應用〉,《佛教圖書館館訊》,第二十四期,2000年12月。
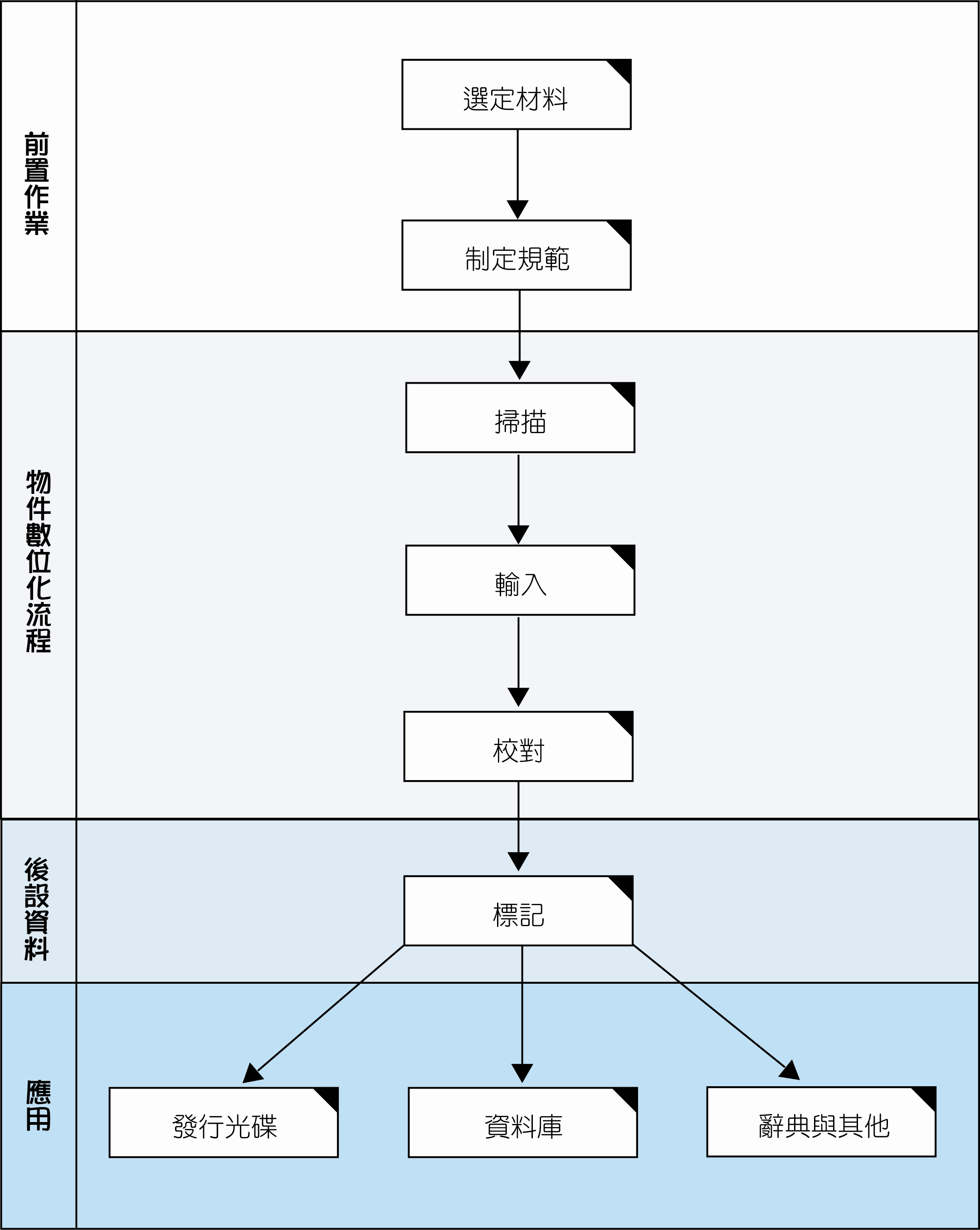
肆、數位化物件程序
原書圖像之掃描之工作,視數位化藏品數量、計畫經費以及成本效益等考量,可選擇自行購買掃描器自製圖像,或是委託外部掃描廠商承包處理。若選擇自行掃描,可購買具備「自動送紙功能」與「自動編號存檔」之掃描器,節省人力。圖書掃描之作業流程【9】如下:
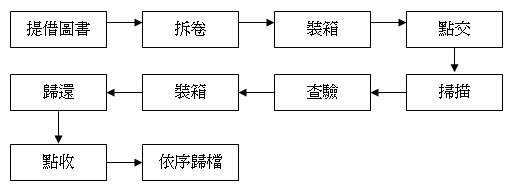
| 書名 | 册數 | 提卷日期 | 提卷人簽名 |
|
點收人簽名
|
備註
|
|---|---|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
二、輸入
(一)人工輸入
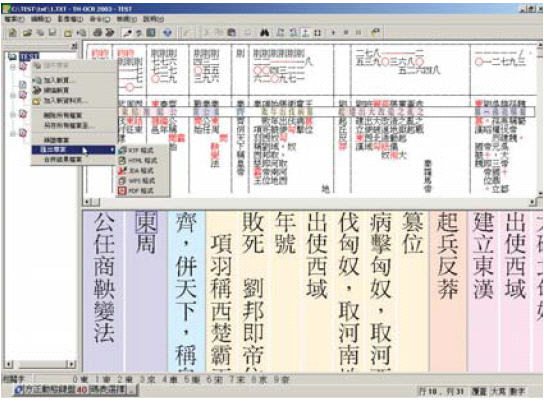
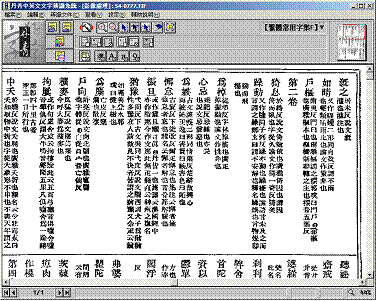
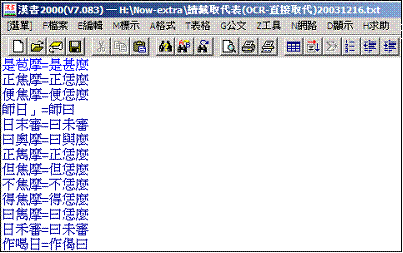
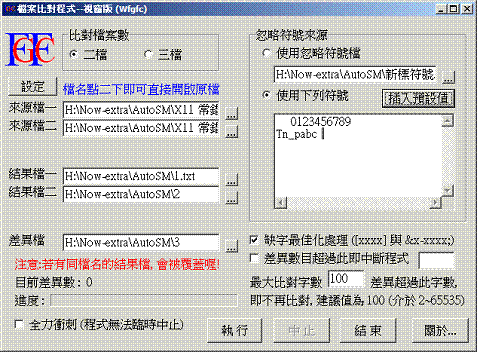
三、校對

圖七、教育部異體字字典畫面
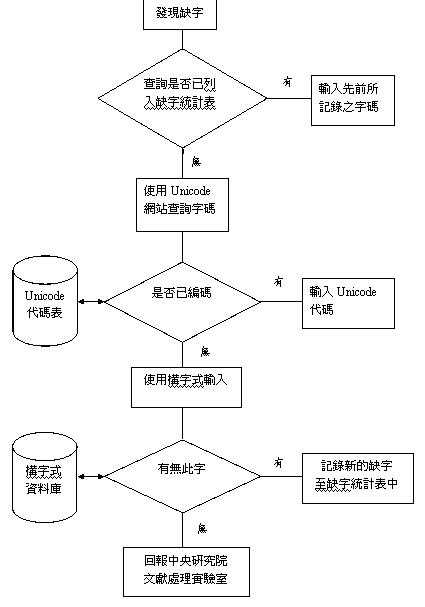
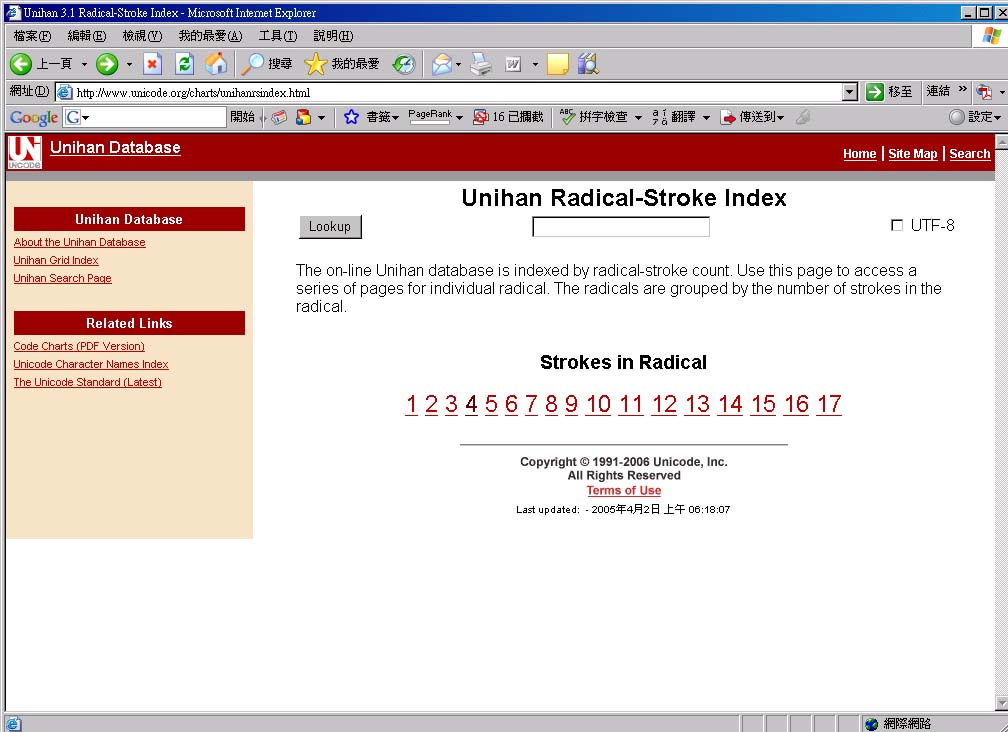
於Unicode網站([19] http://www.unicode.org/charts/unihanrsindex.html)查詢缺字(圖八),先以部首筆畫進入,之後再以扣除部首之外的筆畫查詢,即可找出所遇缺字是否已編入Unicode。而有關中央研究院資訊科學研究所文獻處理實驗室研發之漢字構形資料庫的相關介紹與使用說明,可上其網站([20] http://www.sinica.edu.tw/~cdp/)瀏覽、下載。
(六)套用新式標點
註9:數位典藏國家型科技計畫,〈1-9檔案數位化影像製作文件處理工作場所規範:以外交檔案為例〉,《技術彙編》,2002年。
註10:程婉如,《報紙期刊全文輸入數位化工作流程指南》,2005年,頁18-20。
註11:袁國華,〈建立UNICODE漢字異體字表與異體字辭典相關研究〉,《國家數位典藏通訊》,第三卷第八期,2004年。
註12:國史館台灣文獻館難字處理程序。
伍、後設資料建置
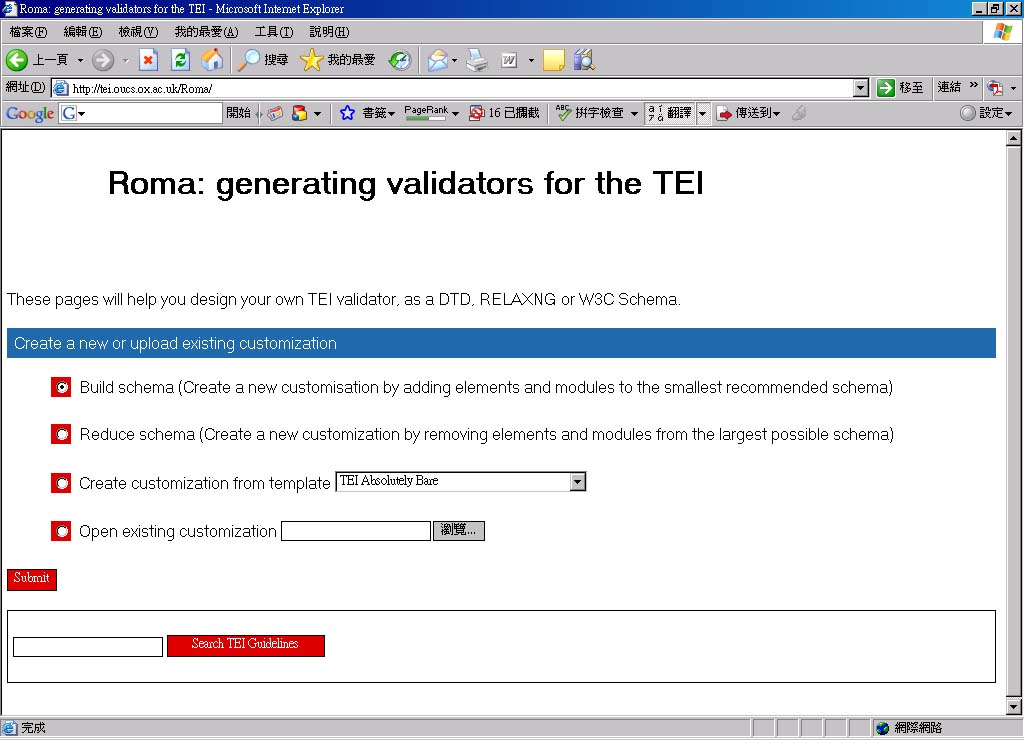
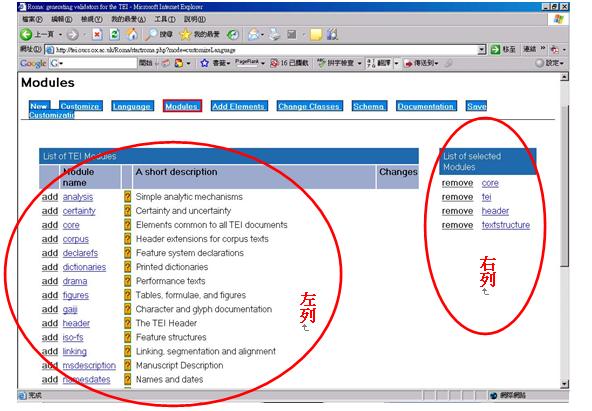
一、文獻語料的專屬後設資料─TEI
|
元素名稱
|
定義
|
範例
|
||||
|---|---|---|---|---|---|---|
|
類型(type)
|
header所加進的檔案類型。
|
語料庫(corpus)
|
||||
|
建立者(creator)
|
指出TEI Header的建立者。
|
|
||||
|
階段(status)
|
說明header是新的或是已經改版過。
|
|
||||
|
建立日期(date.created)
|
指出header第一版的建立日期。
|
|
||||
|
更新日期(date.updated)
|
指出現在版本的建立日期。
|
|
||||
|
檔案描述(fileDesc)
|
描述電子檔案(computer file)本身的完整書目資訊。從這些描述裡,文件的使用者可以得到適當的參考文獻,或當這些檔案由圖書館或檔案館收藏時,館員可以根據此描述建立目錄。這裡的「電子檔案」是指由header所描述的整批文件或檔案,而不管是否分別儲存在數個作業系統下。這個類別也可以描述電子檔案的來源資訊。
|
|
||||
|
|
標題敘述(titleStmt)
|
一組有關作品的標題和負責智識內容者的資訊。
|
|
|||
|
|
題名(title)
|
一件作品的題名,作品可以是文章、期刊、書籍或叢書;標題包含了別名(alternative titles)或副檔名(subtitle)。
|
Two stories by Edgar Allen Poe: electronic version
|
|||
|
|
層級(level)
|
標題的書目層級,可以指出是屬於文章、期刊、書籍、叢書或未出版文獻的題名。
|
|
|||
|
類型(type)
|
題名的類型,依據一些合適的分類標準來分類題名。
|
|
||||
|
作者(author)
|
書目索引裡的作者名稱,包含作品作者的名稱,可以是個人的或團體的名稱。在任何書目資料裡是對負責者的主要敘述。
|
Poe, Edgar Allen(1809-1849)
|
||||
|
贊助單位(sponsor)
|
指出贊助機構或組織的名稱。
|
|
||||
|
主辦單位(funder)
|
為文件或計畫出資的個人、學術機構或組織的名稱。
|
Wellcome Institute for the History of Medicine
|
||||
|
主要建立者(principal)
|
負責建立電子檔案的主要研究人員名稱。
|
Dominik Wujastyk
|
||||
|
負責者敘述(respStmt)
|
提供負責文件內容、版本、紀錄或叢書負責人的敘述。通常作為當作者或編輯者等元素不足以描述或沒有描述時的補充說明元素。
|
|
||||
|
負責內容(resp)
|
以短語的方式描述負責者智識上的工作內容。
|
由—編輯(compiled by)
|
||||
|
姓名(name)
|
|
James D. Benson
|
||||
|
|
類型(type)
|
以短語的方式對物件類型命名。
|
|
|||
|
版本敘述(editionStmt)
|
一組有關文件某版本的資訊。
|
|
||||
|
|
版次(edition)
|
描述某一文件某一版本的特殊性。
|
第二版草稿,較前版大為擴展、改版和修正
|
|||
|
負責者敘述 (respStmt)
|
提供負責文件內容、版本、紀錄或叢書負責人的敘述。通常作為當作者或編輯者等元素不足以描述或沒有描述時的補充說明元素。
|
|
||||
|
名稱(name)
|
|
George Brown
|
||||
|
|
類型(type)
|
以短語的方式對物件類型命名。
|
|
|||
|
負責內容(resp)
|
以短語的方式描述負責者的工作內容。
|
由—全新註釋
|
||||
|
大小(extent)
|
描述電子檔案儲存在某些媒介裡的約略大小,須以合適的單位表示。
|
(1) 4532 bytes
(2) 3200句 |
||||
|
出版描述 (publicationStmt)
|
一組有關電子或其他文件出版或發行的資訊。
|
|
||||
|
|
出版單位 (publisher)
|
負責出版或發行書目項目的組織名稱。
|
牛津大學出版社
|
|||
|
發行者/單位 (distributor)
|
負責文件發行的個人或其他代理人的名稱。
|
Oxford Text Archive
|
||||
|
權威人士(authority)
|
非出版者或發行者,但負責使電子檔案可通行的人或機構名稱。
|
James D. Benson
|
||||
|
|
出版地點 (pubPlace)
|
一個書目項目出版的地點名稱。
|
牛津
|
|||
|
地址(address)
|
提供出版者、組織或個人的郵件或其他地址。
|
21 High Street, Wilmslow, Cheshire M24 3DF
|
||||
|
識別碼(idno)
|
用於識別一個書目項目的標準式或非標準式的號碼。
|
0-19-254705-4
|
||||
|
|
類型(type)
|
識別碼的類型,例如ISBN或其他標準序號。
|
<idno type=’ISBN’>
|
|||
|
取用權(availability)
|
提供一份文件的取用權的資訊,包括使用或發行限制、著作權限等。
|
James D. Benson
|
||||
|
日期(date)
|
|
1989
|
||||
|
|
曆法(calendar)
|
指出時間表示的系統或曆法。
|
|
|||
|
格式(value)
|
以標準的格式表示日期,通常以yyyy-mm-dd表示。
|
|
||||
|
精確度(certainty)
|
描述日期的精確程度。
|
|
||||
|
序號敘述(seriesStmt)
|
有關序號的一組資訊,通常在出版上使用。
|
|
||||
|
|
題名(title)
|
一件作品的題名,作品可以是文章、期刊、書籍或叢書;標題包含了別名(alternative titles)或副檔名(subtitle)。
|
Machine-Readable Texts for the Study of Indian Literature
|
|||
|
|
層級(level)
|
標題的書目層級,可以指出是屬於文章、期刊、書籍、叢書或未出版文獻的題名。
|
<title level="S">
|
|||
|
類型(type)
|
題名的類型,依據一些合適的分類標準來分類題名。
|
|
||||
|
識別碼(idno)
|
用於識別一個書目項目的標準式或非標準式的號碼。
|
1.2
|
||||
|
|
類型(type)
|
識別碼的類型,例如ISBN或其他標準序號。
|
<idno type="vol">
|
|||
|
負責者敘述(respStmt)
|
提供負責文件內容、版本、紀錄或叢書負責人的敘述。通常作為當作者或編輯者等元素不足以描述或沒有描述時的補充說明元素。
|
|
||||
|
負責內容(resp)
|
|
由—所編
|
||||
|
姓名(name)
|
|
Jan Gonda
|
||||
|
|
類型(type)
|
以短語的方式對物件類型命名。
|
|
|||
|
附註敘述(notesStmt)
|
收集有關文件資訊的補充說明以增加書目描述的其他部分。
|
|
||||
|
|
附註(note)
|
包含附註或註釋(annotation)。
|
歷史評註由Mark Cohen提供
|
|||
|
|
類型(type)
|
描述附註的類型。
|
|
|||
|
註解者(resp)
|
說明負責註釋的人員,例如:作者、編輯者、翻譯者等。
|
|
||||
|
地點(place)
|
指示附註出現在來源檔案的位置
|
|
||||
|
下錨處(anchored)
|
說明是否複製的文件為附註顯示了正確的參照位置。
|
|
||||
|
標的結尾處(targetEnd)
|
如果附註沒有包含在文件裡,則說明附註加接範圍的終點。
|
|
||||
|
來源描述(sourceDesc)
|
提供有關電子文件來源的複製文件的書目描述。
|
|
||||
|
|
書目資料(bibl)
|
包含書目資料的粗略描述,其中的次類不一定要明顯標記(tagged)。
|
The first folio of Shakespeare, prepared by Charlton Hinman (The Norton Facsinile, 1968)
|
|||
|
書目結構(biblStruct)
|
包含結構化的書目引用,其中只會出現有關書目的次元素並以特定的順序出現。
|
|
||||
|
完整書目(biblFull)
|
包含書目資料的完整結構,其中會出現TEI檔案描述的所有組成成分。
|
|
||||
|
條列書目(listBibl)
|
將書目引用以條列方式表示。
|
|
||||
|
腳本描述(scriptStmt)
|
包含對口語檔案的詳細腳本的引述。使用在電子檔案的來源文件是口語檔案時。
|
|
||||
|
記錄描述(recordingStmt)
|
描述口語檔案轉寫時的紀錄。使用在電子檔案的來源文件是口語檔案時。
|
|
||||
|
紀錄(recording)
|
描述口語檔案來源的錄音或錄影事件,影音來源可以從大眾傳播上取得。
|
U-matic recording made by college audio-visual department satff, available as PAL-standatd VHS transfer or sound-only casssette
|
||||
|
|
類型(type)
|
說明錄音/影的種類。
|
<recording type=’video’>
|
|||
|
時長(dur)
|
說明錄音/影的時長。
|
<recording dur="30 mins">
|
||||
|
設備(equipment)
|
提供錄音/影設備或媒體的詳細敘述,這些聲音或影像的紀錄是作為口語檔案的來源。
|
數位錄音自FM廣播
|
||||
|
廣播節目(broadcast)
|
描述作為口語檔案來源的廣播節目。
|
主題:Interview on foreign policy
製作單位:BBC Radio 5 主持人:Robin Day 受訪者: Margaret Thatcher 節目名稱:The World Tonight 附註:First broadcast on 27 Nov 1989 |
||||
|
編碼描述(encodingDesc)
|
描述電子檔案和其來源之間的關係。這個類別詳細描述了在轉寫過程中,文件如何標準化、編碼者如何解決原始文件內歧義的問題、應用了何種層級的編碼或分析方法。
|
|
||||
|
|
計畫描述(projectDesc)
|
詳細描述電子檔案編碼的目的,以及電子檔案集結過程的相關資訊。
|
Texts collected for use in the Claremont Shakespeare Clinic
|
|||
|
取樣宣告(samplingDecl)
|
以散文的方式描述建立語料庫時,文本取樣的原理和方法。
|
文件取樣是從開頭算起兩千字
|
||||
|
編輯宣告(editorialDecl)
|
描述當為文件編碼時,所使用的編輯原則與實作。
|
|
||||
|
|
修正(correction)
|
說明在何種情況下以及如何修正文件。
|
拼字錯誤檢查是藉由WordPerfect spelling checker來執行
|
|||
|
|
程度(status)
|
指出應用在文件上的修改程度。
|
<correction status="unknown">
|
|||
|
方法(methond)
|
用於指出文件內標明更動的方式。
|
<correction metnod="silent">
|
||||
|
標準(normalization)
|
指出轉成電子檔案的原始文件內,施行標準化的範圍。
|
藉由韋氏第九版Collegiate字典將字轉成標準美式拼字(Modern American spelling)
|
||||
|
|
來源(source)
|
指出任何施行標準化的權威檔
|
<normalization source="w9">
|
|||
|
方法(methond)
|
用於指出文件內標明標準化的方式。
|
<normalization method="silent">
|
||||
|
引號(quotation)
|
在編輯時,原始檔內引號的應用。
|
所有開引號由參考實體(entity reference) ODQ表示;所有閉引號由參考實體CDQ表示
|
||||
|
|
引號(marks)
|
指出引號在文件內是否被保留作為內容的一部份。
|
<quotation marks="all">
|
|||
|
形式(form)
|
說明引號在文件內指示功能的運作方式。
|
<quotation form="std">
|
||||
|
連字號(hyphenation)
|
摘要敘述原始。
|
|
||||
|
|
行尾(eol)
|
說明文件裡行尾的連字號是否被保留。
|
|
|||
|
斷詞(segmentation)
|
描述文件斷詞的原則,例如是依句子、聲調單位或字素圖層等。
|
|
||||
|
標準值(stdVals)
|
當使用標準化的日期或數字表示時,指出使用的格式(format)。
|
|
||||
|
詮釋(interpretation)
|
描述除了轉譯以外,任何加在文件上的分析或詮釋資訊的內容。
|
第四部份的言談分析是以手寫方式加入,還未被檢查
|
||||
|
標籤宣告(tagsDecl)
|
詳細描述應用在SGML文件裡標籤的。
|
|
||||
|
|
翻譯(rendition)
|
提供有關一個或多個元素欲轉成樣式的資訊。
|
|
|||
|
標籤使用方式(tagUsage)
|
文件內特定元素的使用資訊。
|
只用來加標籤在複製文件裡的斜體字
|
||||
|
|
(gi)
|
標籤所標示的元素名稱(一般辨識名稱)。
|
<tagUsage gi="p">
|
|||
|
(occurs)
|
文件內元素的出現次數。
|
<tagUsage occurs="28">
|
||||
|
識別(ident)
|
在全球識別屬性(global id attribute)擁有區辨值的文件內,元素的出現次數。
|
<tagUsage ident="321">
|
||||
|
翻譯(render)
|
指出「翻譯<rendition>」元素的識別,而翻譯元素是定義元素是如何被翻譯的。
|
<tagUsage render="style1">
|
||||
|
參照宣告(refsDecl)
|
說明如何為這份文件建立正式的參照(canonical references)。
|
|
||||
|
|
檔案類型(doctype)
|
說明在參照宣告內的檔案類型。
|
<refsDecl doctype="TEI.2">
|
|||
|
階梯式(step)
|
指出由階梯式方法定義的正式參照的一個構件。
|
|
||||
|
|
參照單位(refunit)
|
在正式參照中,給予這步驟所識別出的單位(書、章、詩篇canto、詩節verse)命名。
|
<step refunit="chapter" >
|
|||
|
長度(length)
|
指出參照構件的固定長度。
|
<step length="3" >
|
||||
|
定界(delim)
|
提供跟隨在參照構件後的定界線(delimiting string)。
|
<step delim=":" />
|
||||
|
起點(from)
|
指出在正式參照裡,藉由此步驟參照的起點。
|
<step from="DESCENDANT" (1 DIV2 N %2)" />
|
||||
|
終點(to)
|
指出在正式參照裡,藉由此步驟參照的終點。
|
<step to="DITTO"/>
|
||||
|
里程碑式(state)
|
指出由里程碑式方法定義的正式參照的一個構件。
|
|
||||
|
|
版本(ed)
|
指出里程碑方式應用在何種版本上。
|
<state ed="first"/>
|
|||
|
單位(unit)
|
指出在這里程碑上什麼部份被改變了。
|
<state unit="page"/>
|
||||
|
長度(length)
|
指出參照構件的固定長度。
|
<state length="2"/>
|
||||
|
定界(delim)
|
提供跟隨在參照構件後的定界線(delimiting string)。
|
<state delim="."/>
|
||||
|
類別宣告(classDecl)
|
以一或多個分類法定義檔案內的分類碼。
|
|
||||
|
|
分類法(taxonomy)
|
定義類別來分類文件,可以不明顯地藉由書目索引,或明顯地採結構化分類
|
|
|||
|
類別(category)
|
包含個別的描述類別,可能在使用者定義的分類法內,套合在superordinate類別裡。
|
|
||||
|
類別描述(catDesc)
|
描述文件分類裡的一些類別,可以以短文的形式或藉由使用在TEI正式檔案描述(textDesc)的狀況參數(situational parameters)描述。
|
報紙報導(Press Reportage)
|
||||
|
特徵系統宣告(fsdDecl)
|
識別出特徵系統宣告,其宣告包含對特徵結構的特定類型的定義。
|
|
||||
|
|
類型(type)
|
指出記錄在FSD內特徵結構的類型。這將會是至少一個特徵結構裡的類型屬性值。
|
<fsdDecl type=’myA1′>
|
|||
|
特徵系統宣告(fsd)
|
指出包含特徵系統宣告的外部實體。在檔案的DTD次集合的實體宣告必須和系統內具有檔案的實體名稱相關連。
|
<fsdDecl fsd=’myFeatures’/>
|
||||
|
韻文宣告(metDecl)
|
當韻文的型態是以結構化的元素屬性表示出來時,此元素記錄被運用以顯示韻文型態(metrical pattern)的符號。
|
|
||||
|
|
類型(type)
|
指出符號是否表達了抽象的韻律形式(metrical form),真正的韻律展現(prosodic realization),或者韻律架構(rhyme scheme),或一些相關的組合。
|
<metDecl type="MET REAL">
|
|||
|
型態(pattern)
|
指出規則性的表示方法來定義對符號的合法值。
|
<metDecl pattern="((1| 0)+\ |?/?)*">
|
||||
|
象徵(symbol)
|
記錄在韻文符號內,特定字串的重要性,可以明顯表示或藉由在同一個metNotation內的象徵元素。
|
韻律顯著(metrical prominence)
|
||||
|
|
內含值(value)
|
指出被紀錄的字元或字串。
|
<symbol value="1">
|
|||
|
終點(terminal)
|
指出象徵符號是由其他符號定義(terminal=N)或以描述法(prose)定義(terminal=Y)。
|
<symbol terminal="y">
|
||||
|
文件變體編碼(variantEncoding)
|
宣告變體文件的編碼方法。
|
|
||||
|
|
方法(method)
|
指出變體裝置的編碼方法。
|
|
|||
|
地點(location)
|
指出裝置(apparatus)是隨檔案運作出現或在檔案運作外圍出現
|
|
||||
|
文件描述(profileDesc)
|
提供一份文件非書目部分的詳細描述,特別是所使用的語言和次要語言,文件建立的情況、參與者以及其背景。
|
|
||||
|
|
建立(creation)
|
有關一份文件建立的資訊。
|
<date value="1992-08">1992年8月</date>
<rs type="city">新墨西哥州,Taos城</rs> |
|||
|
使用的語言(langUsage)
|
包含一組有關描述文件的主要語言、次要語言、登錄者、方言等的資訊。
|
|
||||
|
|
語言(language)
|
描述文件內單一的語言或次要語言。
|
加拿大商用英語(Canadian business English)
|
|||
|
|
書寫系統宣告(wsd)
|
為包含書寫系統宣告的實體,用來顯示文件上的語言。
|
<language wsd="wsd.en">
|
|||
|
使用法(usage)
|
指出文件內使用某語言的冊數所佔的約略百分比。
|
<language usage="20">
|
||||
|
文件類別(textClass)
|
一組描述文件性質或標題的資訊,可以藉由標準化的分類架構來描述,例如thesaurus等。
|
|
||||
|
|
關鍵詞(keywords)
|
含有關鍵詞或短語的列表,用來指出一份文件的主題或性質。
|
|
|||
|
|
架構(scheme)
|
定義關鍵詞時所依據的控制詞彙。
|
<keywords scheme="lcsh">
|
|||
|
分類碼(classCode)
|
依據一些標準分類系統為文件訂定分類碼。
|
005.756
|
||||
|
|
架構(scheme)
|
指出使用的分類系統或分類法。
|
<classCode scheme="ddc19">
|
|||
|
類別參照(catRef)
|
一些分類學上所定義的一個或多個類別。
|
|
||||
|
|
目標(target)
|
指出有關的類別。
|
<catRef target="b12 b15">
|
|||
|
架構(scheme)
|
指出定義類型集所依據的分類架構。
|
<catRef scheme="brown"/>
|
||||
|
文件描述(textDesc)
|
提供依據狀況參數(situational parameters)表示的文件描述。
|
|
||||
|
背景描述(settingDesc)
|
描述語言互動(language interaction)發生時的背景,可以是散文式描述或利用一系列元素來描述。
|
|
||||
|
筆跡(handlist)
|
包含描述來源筆跡的元素列表。
|
|
||||
|
改版描述(revisionDesc)
|
允許編碼者提供在電子檔案發展過程中,檔案變動的歷史。改版歷史對版本控制(version control)和解決文件歷史的問題都很重要。
|
|
||||
|
|
變更(change)
|
摘要描述一份多位研究者所共有的電子文件的變更或改版的內容。
|
|
|||
|
|
日期(date)
|
以任何形式表示的日期。
|
5/25/91:
|
|||
|
|
曆法(calendar)
|
指出時間表示的系統或曆法。
|
|
|||
|
格式(value)
|
以標準的格式表示日期,通常以yyyy-mm-dd表示。
|
|
||||
|
精確度(certainty)
|
描述日期的精確程度。
|
|
||||
|
負責者敘述 (respStmt)
|
提供負責文件內容、版本、紀錄或叢書負責人的敘述。通常作為當作者或編輯者等元素不足以描述或沒有描述時的補充說明元素。
|
<name>EMB</name>
<resp>ed.</resp> |
||||
|
項目(item)
|
包含一列表的一個組成部分。
|
檔案格式更新
|
||||

(五)轉出HTML格式
二、製作成品光碟

三、發展相關百科、字(辭)典
在全文數位化過程中,校對時記錄之缺字、異體字,標記時詮釋、註解的詞句語法,以及權威控制的詞條、字彙,都可以加值成提供資訊與知識的線上工具書。
[26] (目錄)
柒、數位資料保護
一、限制使用端IP
有些圖書館或是博物館會採用付費或是限制使用者IP的方式,管理館藏文獻的資源流通。選擇以此方式來限制資源流向的機關單位,通常是其館藏具有特殊、珍貴性質,或是牽涉著作權、授權等法律問題。

三、無償使用
註13:
此部分,我們針對全文數位化工作所需之相關器材設備,進行選購說明。主要設備包括影像掃描器以及電腦的軟硬體設備。
市面上掃描器分有桌上型平台掃描器、桌上型自動進紙式掃描器、桌上型無邊縫掃描器、以及滾筒掃描器。如果欲進行全文數位化的單位想自行掃描,建議使用自動進紙式掃描器,並搭配自動編號存檔之功能,能夠有效節省掃描時間,簡化掃描工作。
(三)電腦軟體的選擇
([28] http://www.adobe.com/tw/products/photoshop/)。
二、成本分析
|
作業項目
|
價格
|
|---|---|
|
掃描 |
委外掃成300dpi黑白影像檔,價格為NT1.5元/頁(A4)
|
|
輸入
|
台灣:NT50元/1000字 |
|
中國大陸:NT25元/1000字
NT15000元/冊
|
[29] (目錄)
過去,台灣在漢籍全文的數位化領域,不論質量,皆處於獨步全球的地位;然而現今,中國大陸也逐漸進行相同的全文數位化工作,產量方面的表現尤其驚人,並非台灣所能匹敵。有鑑於此,國內長期從事全文數位化的單位、機構,在質與量難以兼得的情況下,莫不選擇投入大量時間精力與智慧腦力,以製作出高水準、高品質的全文資料庫為計畫目標,而非汲汲營營趕製產量。此數位化工作流程指南,亦抱持高品質高水準之觀念宣導,在全文數位化程序上,著重文件標記之詮釋資料的介紹。如前面後設資料之章節所述,文件標記是提升電子全文研究價值與應用廣度的必備利器,而現有文件標記系統裡,又以本文所介紹之TEI最為人文學者以及圖書、博物館界所推崇,希望所有已經或是即將進行全文數位化工作之計畫,都能將之納入標準作業程序,有利數位化成品日後之再利用。
拾、參考資料
1. 中央研究院文獻處理實驗室,《漢字構形資料庫使用手冊》,2002年。
2. 林彥宏,《文書檔案數位化工作流程參考標準》,2005年12月。
3. 香光尼眾佛學院圖書館,《佛教圖書館館訊》,第二十四期,2000年12月。
4. 香光尼眾佛學院圖書館,《佛教圖書館館訊》,第十八/十九,1999年 9月。
5. 香光尼眾佛學院圖書館,《佛教圖書館館訊》,第十五,1998年 9月。
6. 香光尼眾佛學院圖書館,《佛教圖書館館訊》,第十四期,1998年 6月。
7. 香光尼眾佛學院圖書館,《佛教圖書館館訊》,第三十二期,2002年12月。
8. 香光尼眾佛學院圖書館,《佛教圖書館館訊》,第三十五/三十六期,2003年12月。
9. 香光尼眾佛學院圖書館,《佛教圖書館館訊》,第四十期,2004年12月。
10. 國立臺灣大學典藏數位化計畫,《台灣文獻文物典藏數位化計畫》,2006年11月20日,
<[31] http://140.112.113.4/project/default.asp>。
11. 莊德明,〈漢字資訊化的困境及因應:談如何建立漢字知識庫〉,第二屆漢字文化節學術研討會, May 2006.。
12. 陳秀華,《書畫數位化工作流程參考標準》,2005年12月。
13. 程婉如,《報紙期刊全文輸入數位化標準作業流程參考》,2005年12月。
14. 數位典藏國家型科技計畫,《技術彙編》,2002年。
15. 數位典藏國家型科技計畫,《國家數位典藏通訊》,第三卷第八期,2004年。
16. 數位典藏國家型科技計畫內容發展分項計畫,《數位典藏叢書──數位化工作流程:漢籍全文主題小組》,2006年1月。
[32] (目錄)
Article printed from 拓展台灣數位典藏: http://content.teldap.tw/index
URL to article: http://content.teldap.tw/index/?p=347
URLs in this post:
[1] 壹、前言: http://content.teldap.tw/index/?p=347&page=2
[2] 貳、數位化工作流程圖: http://content.teldap.tw/index/?p=347&page=3
[3] 參、前置作業: http://content.teldap.tw/index/?p=347&page=4
[4] 肆、數位化物件程序 : http://content.teldap.tw/index/?p=347&page=5
[5] 伍、後設資料建置: http://content.teldap.tw/index/?p=347&page=6
[6] 陸、資料庫與其他應用: http://content.teldap.tw/index/?p=347&page=7
[7] 柒、數位資料保護: http://content.teldap.tw/index/?p=347&page=8
[8] 捌、設備與成本分析 : http://content.teldap.tw/index/?p=347&page=9
[9] 玖、結語: http://content.teldap.tw/index/?p=347&page=10
[10] 拾、參考資料: http://content.teldap.tw/index/?p=347&page=11
[11] 〈目錄〉: http://content.teldap.tw/index/?p=347&preview=true#01
[12] (目錄) : http://content.teldap.tw/index/?p=347&preview=true#01
[13] http://www.sinica.edu.tw/ftms-bin/new/test/ftmsw3: http://www.sinica.edu.tw/ftms-bin/new/test/ftmsw3
[14] http://content.teldap.tw/main/doc_detail.php?doc_id=548: http://content.teldap.tw/index../../../../../../main/doc_detail.php?doc_id=548
[15] http://www.cbeta.org/data-format/rare-rule.htm: http://www.cbeta.org/data-format/rare-rule.htm
[16] http://content.teldap.tw/main/doc_detail.php?doc_id=553: http://content.teldap.tw/main/doc_detail.php?doc_id=553
[17] http://www.cbeta.org/index.htm: http://www.cbeta.org/index.htm
[18] http://140.111.1.40/: http://140.111.1.40/
[19] http://www.unicode.org/charts/unihanrsindex.html: http://www.unicode.org/charts/unihanrsindex.html
[20] http://www.sinica.edu.tw/~cdp/: http://www.sinica.edu.tw/~cdp/
[21] http://www.tei-c.org/: http://www.tei-c.org/
[22] http://tei.oucs.ox.ac.uk/Roma/: http://tei.oucs.ox.ac.uk/Roma/
[23] http://www.ultraedit.com/: http://www.ultraedit.com/
[24] http://www.oxygenxml.com/index.html: http://www.oxygenxml.com/index.html
[25] (目錄): http://content.teldap.tw/index/?p=347&preview=true
[26] (目錄): http://content.teldap.tw/index/?p=347&preview=true
[27] http://creativecommons.org.tw/: http://creativecommons.org.tw/
[28] http://www.adobe.com/tw/products/photoshop/: http://www.adobe.com/tw/products/photoshop/
[29] (目錄): http://content.teldap.tw/index/?p=347&preview=true
[30] (目錄): http://content.teldap.tw/index/?p=347&preview=true
[31] http://140.112.113.4/project/default.asp: http://140.112.113.4/project/default.asp
[32] (目錄): http://content.teldap.tw/index/?p=347&preview=true
Click here to print.