|
數位島嶼電子報 第二十八期 (2008-06-20) |
 |
 |
博物館電腦網路協會台灣分會(MCN Taiwan)標準規範主題小組2008.04.16工作坊紀實
邂逅標準—
博物館電腦網路協會台灣分會(MCN Taiwan)標準規範主題小組2008.04.16工作坊紀實
文/博物館電腦網路協會臺灣分會 - 蔡幸真
博物館電腦網路協會台灣分會(MCN Taiwan)於今年4月中,由標準規範主題小組舉辦了首次小組工作坊,揭開本會今年度小組活動的序幕。35位來自多個博物館、圖書館、檔案館、學校與業界人士齊聚一堂,認識標準,也認識彼此。
會議開始,由標準規範主題小組召集人,也是數位典藏與數位學習國家型科技計畫計畫辦公室專案經理陳淑君介紹了MCN Taiwan成立的背景,以及標準規範主題小組未來可能的走向。MCN是一個以北美為主、歷史悠久的國際組織,旨在推廣博物館及文化資產機構運用新興資訊科技,於去年11月年會上才剛熱鬧舉辦成立40週年的慶祝大會。
標準規範主題小組預計每兩個月舉辦一次聚會活動,作為台灣文化資產機構探討標準的平台,期盼將數位典藏國家型科技計畫自91年以來所累積的相關知識與經驗,向外推廣至未能參與數位典藏計畫的文化資產機構,曾參與數位典藏計畫的成員,則可分享實際經驗,或就實際遭遇的問題進行更深度的探討或實驗。小組中的發現或成果,也將透過MCN所舉辦的年會輸出到國外。
“許多與會成員最關心的問題,是如何設計資料庫與後設資料的欄位”
簡短的介紹之後,由參與小組的成員輪流進行自我介紹。本次參與成員中,有34位來自台灣地區14個文化資產相關機構,還有1位遠從澳門藝術博物館而來,約三分之二曾參與數位典藏工作。小組成員的專業領域亦相當廣泛,包括生物、藝術史、文物保存與管理、圖書文獻數位化、法律、資料庫設計、網頁管理等。
許多與會成員最關心的問題,是如何設計資料庫與後設資料的欄位,方便使用者查詢、學習或吸收有系統的知識。台博館助理研究員林芙美提到,在參與藏品管理系統開發的過程中,深深感到建置、維護數位化藏品資料外,若能提升對應用層面的重視,譬如在數位化過程中納入主題性描述,透過系統自動化的方式匯集相關知識,形成主題,應能讓這些辛苦建置的數位化成果,以相對迅速的方式提供對藏品知識較不熟悉的民眾有脈絡的知識。
此外,國史館采集處蒐藏科科長呼瑞娟談到,自93年總統副總統管理條例頒佈施行後,國史館的典藏品從原本類型較一致的史料檔案,擴展到多種不同的類型,包括各種器物與史料等,因此特別關心如何規劃可以適用橫跨各種藏品類型的資料庫。也有許多成員提到,希望透過這個小組,學習後設資料與國際標準的相關知識,或是藉由小組聚會的交流分享,瞭解其他單位的經驗,互相學習。
“標準規範的存在,便是確保溝通的雙方使用相同的語言”
專題演講的部分,邀請到中研院任職於計算中心,也是數位典藏與數位學習國家型科技計畫後設資料工作組計畫主持人陳亞寧擔任講師,講題為「標準的重要性及影響力」。陳講師的演講深入淺出,經常運用靈活的比喻及日常生活的案例,將標準規範的基本知識介紹給與會成員。
演講以「一對戀人相約於某月某日私奔」的情境開始,帶出人們對於語言的解讀必須要有一定的共識,才能彼此溝通,而標準規範的存在,便是確保溝通的雙方使用相同的語言。譬如上述情境中的男女,如果彼此對「私奔」二字的解讀不同,可能便無法順利完成他們的行動。而即便對「私奔」的定義相同,若兩個人對於日期的解讀沒有共識,可能有「等無人」的情況發生。譬如「03 08 1998」的日期標示,對英國與美國國民來說意義就不同,一個會解讀為3月8日,一個會認為是8月3日,兩者一差就是5個月的光陰。
本次演講中,陳講師介紹了國際上對於標準的認定、目的與類型,並聚焦在後設資料標準的類型、功用與目的。隨後介紹一些博物館相關的後設資料標準,包括CDWA、CDWA Lite、CCO、AAT、ULAN等。
博物館藏品資料互通實驗計畫
標準規範小組推出了一個「博物館藏品資料互通實驗計畫」(MuseFusion, Museum Collection Fusion Project),也在本次的工作坊中,由本小組聯絡人,數位典藏與數位學習國家型科技計畫後設資料工作組城菁汝女士,進行計畫介紹。本計畫是以研究為目的,測試各式國際標準在實際應用時可能遇到的問題及成效,同時觀察學習目前國際上相關實驗計畫。期待小組成員透過小組參與合作,吸收新知、進行交流與分享。
有興趣的小組成員可自由參與本實驗計畫,只需自備兩件特色藏品,不論是自己拍攝或是機構內的特色典藏皆可,把藏品後設資料填入本計畫的實驗平台裡,僅需填寫一次,將來就可以運用這個平台內的資料做多種不同的觀察與學習。標準小組預計五月份會加開一個資料填寫工作坊,邀請有興趣參與的小組成員實際在電腦上操作,學習實驗平台的使用方式。
後記
本次工作坊報名踴躍,但為維護討論品質,設有名額限制,無法讓所有報名者都出席,非常感謝許多額滿後報名成員的諒解。本次出席的成員,計有國立台灣博物館、國立歷史博物館、林業試驗所森林生物組、檔案管理局、台灣大學圖書館、師大圖書資訊研究所、國立故宮博物院、中央研究院、國立台灣藝術大學圖文傳播學系、國史館、寰璟生活情資整合有限公司、宜蘭縣公正國小、國立交通大學傳播科技學系、中央警察大學世界圖書館(世界警察博物館)、國立自然科學博物館、澳門藝術博物館。
博物館電腦網路協會臺灣分會後續將持續舉辦系列活動,歡迎有興趣的朋友一起來參加。詳情請洽: http://mcntw.ndap.org.tw,加入會員,我們會隨時將最新消息寄給您。
2008數位島嶼攝影比賽,首獎10萬元,等你來挑戰!
2008 第三屆數位島嶼攝影比賽 《 按戀‧數位島 》
比賽主題: 下列主題以系列作品方式(5~15張)呈現多視角的台灣風貌。
1. 城市: 經由歷史文化醞釀,每座城市都擁有不同的姿態與氣質,《數位島嶼》邀您拿起相機,透過鏡頭描繪您所看見的城市風情。
2. 交通: 藉由交通工具,人們得以翻越山谷、悠遊水上、甚至翱翔天際。《數位島嶼》與您一同記錄台灣的交通景觀。
3. 校園: 吟唱歷史人文,學習數理科技,校園裡藏著多少動人記憶?!《數位島嶼》與您一起補捉校園內生命跳動的顏色。(限大學以上校園景象)
參加資格:
凡愛好攝影之個人。 (本院同仁、主辦單位工作人員及家屬不得參賽)
作品規格:
1.每人可參加主題不限,可重複參加不同主題,兼或同一主題有多套作品參賽,但每一套需為系列作品。
2.每套作品張數 5 ~ 15 張。
3.作品以正片、負片或數位格式拍攝皆可。
4.數位作品原始檔案大小為500萬畫素以上規格之JPG (fine、high quality)。
5.作品為正片、負片或照片者,需掃瞄成解析度600dpi之電子檔。
收件日期:
即日起至97年 8月 8 日 (以郵戳為憑)
收件方式:(兩者皆須完成)
1.數位檔案:於97年 8月8日前(系統時間為準,煩請儘早上傳),請先加入數位島嶼會員(按我加入),並將作品上傳至主辦單位之「數位島嶼」網站-會員聚落,並於填寫作品資料「標籤」欄中,完整填入:「2008數位島嶼攝影比賽-城市」、「2008數位島嶼攝影比賽-交通」、「2008數位島嶼攝影比賽-校園」(視參賽組別而定),填寫不完全者,視同報名未成功,不納入比賽。
2.郵寄資料:
(1) 報名資料:每套作品限填一張報名表(按此下載)。
(2) 實體相片:
‧每張作品請沖洗為8×10吋。
‧背後需標上編號順序,且附上作品數位檔案光碟。
‧每張作品至少3MB以上,或未經壓縮之原始檔,供展覽活動輸出使用。
‧300字以上創作說明。(實際展出形式依照主辦單位規劃。)
(3) 其他注意事項:
‧參賽之作品,請以厚紙板自行完封包裝。若有黏貼或因繳交作品尺寸過大造成作品毀損之情形,主辦單位概不負責。
‧正式參賽文件必須包括報名表及參賽作品。請確實填寫報名表格,連同作品一併寄回 (報名表格可自行複印)。若因未標明清楚而造成系列作品遺失或作者認定困難,主辦單位概不負責。
‧郵寄資料於收件截止日前寄至主辦單位,郵寄地址為115台北市南港區研究院二段130號 中央研究院歷史語言研究所文物館403室,收並請於信封上註明「拓展台灣數位典藏計畫分項 2008 數位島嶼攝影比賽」收。
3.上述資料(數位檔案及郵寄資料)限於期限內繳交完畢,缺少任何一項即視為報名不完整,取消比賽資格。
4.參賽作品概不退還。
獎勵辦法:《每一主題》
第一名:獎金新台幣10萬元整,獎狀乙紙。
第二名:獎金新台幣5萬元整,獎狀乙紙。
第三名:獎金新台幣3萬元整,獎狀乙紙。
優選 (5名):獎金新台幣5仟元整,獎狀乙紙。
入選作品(數名):精美紀念品 ,獎狀乙紙。
附註:
1. 得獎人員所獲獎金,應依法扣除所得稅。
2. 優選以上得獎人(含跨組),不得重複。若有重複者取最高獎次,並依序遞補。
拍攝期間: 不限。
評審:
由主辦單位聘請專家成立評審委員會,採初審及複審兩階段進行評選。
得獎公佈:
於評審完成後一週內通知得獎人,並於網站及相關電子報公佈得獎名單
數位典藏國家型科技計畫‧拓展台灣數位典藏分項計畫
數位島嶼
頒獎日期與地點:
97年8月23日於 華山創意文化園區 4A 展場,舉行頒獎典禮。
注意事項:
1. 參賽作品需未經公開發表,翻拍拷貝;經查有前述情事者,一律取消資格,得獎作品則由主辦單位追回該獎項,獎位不予遞補。
2. 作品一經投稿,即不可由「數位島嶼」網站中撤除。
3. 嚴禁盜用他人作品參賽,違者除取消得獎資格,追回獎品、獎狀外,其違反著作權法之責任概由參賽者自負,與主辦單位無關。
4. 得獎作品,著作權歸主辦單位所有,主辦單位得使用該作品進行相關非商業性宣傳、各種形式之展出等。
5. 凡參加本競賽活動,視同承認主辦單位訂定之各項規定。
6. 請詳閱簡章與數位島嶼網站公佈,若有修改,以網站公佈為主,恕不另行通知。
指導單位:
行政院國家科學委員會
主辦單位:
數位典藏與數位學習國家型科技計畫‧拓展台灣數位典藏計畫
子計畫二、數位內容公開徵選計畫
|
 |
台灣本土音樂家之影音典藏—李泰祥大師計畫介紹
文/國立交通大學圖書館 黃明居、林孟玲
台灣在1970年代音樂家與藝文界人士有感於西洋音樂充斥於市面,年輕人與中國文學和音樂漸行漸遠,於是有人主張要唱自己的歌,表現對民族與鄉土的關懷,民歌遂在校園與民間掀起一陣風潮,其中大家耳熟能詳的「橄欖樹」,至今仍被大家所傳唱,其優美動人的旋律出自於作曲 交通大學近年來積極提倡人文關懷與藝術教育,以均衡科技創新與人文藝術的共同發展,希望能夠為台灣的文化資產保存與傳承盡一份責任。交大圖書館執行數位典藏計畫多年,將成果建置成「浩然藝文數位博物館」提供讀者透過網路得以共享此藝術資源(http://folkartist.e-lib.nctu.edu.tw)。2006年因緣際會認識了 95年度計畫的第一期主要以民歌為主,由李老師精選民歌初期,最能展現其風行年代特色的25首民歌為數位化標的,歌曲有:橄欖樹、一條日光大道、告別與不要告別、雁、晨光、海棠紋身、都市旋律、青夢湖、傳說、答案、你是我所有的回憶、觀音、蒹葭、水天吟、祝福、山之旅、去罷、浮雲歌、歡顏、三月的風、鷺鷥、今年的湖畔會很冷、他的眸子、菊嘆、春天的故事。計畫係以李老師所提供的各式樂譜,涵蓋簡譜、人聲演唱樂譜、鋼琴譜、絃樂譜、室內樂譜、交響樂譜、各種分譜等文件掃瞄為主,並蒐集其相關的影音資料,輔以其所提供的唱片、照片、演出紀錄、創作背景說明,另一方面從完整音樂家生平資料,能有助於作品的瞭解,計畫同時整理李老師大事年表、作品一覽表、新聞事件、期刊資料,提供一般民眾做音樂賞析,或音樂教育者研究與教學更完整的圖譜(成果請見圖一~圖三,詳細網頁請瀏覽http://lth.e-lib.nctu.edu.tw/)。

圖一、網頁首頁
圖二、原稿樂譜
圖三、相片集錦
|
 |
資料庫初體驗(4)
書同文,編碼大不同
何謂編碼?
有哪些種類的編碼方式?
由於電腦並不像人腦,可以理解人的語言或文字,因此為了讓電腦接受到使用者輸入的訊息,所有的資料都會被轉換成0與1的數字後才進行處理,故有人說電腦是由0與1所組成的,而資料都會被轉換成0與1的過程,也就是所謂的編碼。在許多情況下,電腦編碼方式所能容納的字數是有限的,所以沒辦法涵蓋完整想要表示的字,例如:廣泛被使用的Big5編碼只是包含中文的常用字及符號而已,故以Big5編碼為主的電腦,僅能處理中文字所有集合(字集)中的一小部份。當然也有一個編碼包含許多字集的,例如Unicode的目標是包含所有字集。
英文系統內一樣有編碼。以一字節八位元(8 bits)排列,共可得256個組合,即0至255。但由於英文字母加上大小寫及常用的符號後,也不到128個,所以在早期的電腦系統內,只用了0至127(即十六進制的00至7F)。西文由於基本字符少,所以用2的8次冪就能包涵所有的字元。它的內碼集共0至255,名為ASCII。
現行的系統下,在同一種環境中,只能顯示一種編碼,所以只要這個編碼沒支援的字,就沒辦法顯示。目前常見之中文編碼有Big5(臺灣)、GB 2312(中國大陸)、國際標準Unicode等等,茲分別簡介如下:
● Big5
Big5編碼是使用繁體中文社群中最常用的電腦漢字字符集標準,共收錄13,053個漢字,其中有2字為重複編碼。是在1984年由中華民國財團法人資訊工業策進會為五大中文套裝軟體所設計的中文內碼,所以就稱為Big5中文內碼,雖然五大套裝軟體並沒有成功,但Big5編碼卻深遠地影響正體中文電腦內碼,直至今日。Big5後來被人按英文字序譯回中文,以致現在有『五大碼』和『大五碼』兩個中文名稱。
● GB 2312
GB 2312是一個簡體中文字符集的中國國家標準,全稱為《信息交換用漢字編碼字符集·基本集》,又稱為GB0,由中國國家標準總局發佈,1981年5月1日實施。GB 2312編碼通行於中國大陸,新加坡等地也採用此編碼,中國大陸幾乎所有的中文系統和國際化的軟體都支持GB 2312。GB 2312標準共收錄6,763個漢字,但是對於人名、古漢語等方面出現的罕用字,GB 2312不能處理,這導致了後來GBK及GB 18030漢字字符集的出現。
● Unicode
Unicode是一種在電腦上使用的字元編碼。它為每種語言中的每個字元設定了統一且唯一的二進位編碼,以滿足跨語言、跨平台進行文本轉換、處理的要求。隨著電腦工作能力的增強,Unicode也在面世以來的十多年裡得到普及。由於Unicode在其編碼中同時容納了全世界各種語言的字元和符號,因此已成為國際常用的交換碼標準。目前Unicode在漢字的支援方面已經定義超過七萬多個字元,收納的字遠多於Big5,且收納字的範圍還在繼續增補中,因此也的確解決了某些層次字形編碼不足的問題,並且在許多系統的支持下,在資訊交換上也的確有其便利性。
中文字編碼存在哪些問題?
電腦的編碼系統原本是採用一個字對一個碼,才能夠在電腦上顯示出來,人類雖然看得懂字形,但是電腦只能看懂編碼,且能夠被放到電腦的數量,受限於編碼空間的限制,必須挑選適當的文字或符號放到電腦,再將這些文字或符號加以編碼。其他沒有被收錄的文字,如果使用者需要在電腦上使用,將無法順利於電腦上表達出來,這些文字則稱為缺字。
由於數位典藏機構需要將大量的古代文獻數位化儲存,而古籍中又包含了大量的罕用文字,故經常發生缺字問題,所以缺字問題也成為漢字數位化過程中最急迫的問題之一。為了解決缺字問題,最常用的方法是利用使用者造字區內自行新增所需之缺字,但此方法在面對資料檢索或是交換時,因另一方可能沒有相同的造字檔,而遭遇資料錯誤、無法讀取或文字空白等問題,故並未徹底解決缺字問題,再加上當使用者造的字越來越多時,複雜的管理問題也隨之而來。
我們以『游錫堃』、『王建煊』這兩個姓名來舉例,『堃』、『煊』這兩個字在Big5編碼中是不存在的,而在Unicode編碼中是存在的。所以當我們所編輯的文件格式預設編碼為Big5時,這些未存在於Big5編碼中的文字會以問號顯示;而在HTML網頁原始碼的文件上,則會以該字的跳脫字元格式(Escapes)來表示,例如:『堃』會表示為『堃』、『煊』會表示為『煊』。若需要正確顯示這些文字,只需要將文件的編碼格式設定為包含該文字的編碼格式,例如:Unicode。
數位典藏機構所提供的解決方案?
數位典藏的古籍資料中有相當數量的缺字存在,所以在缺字的解決上必須有一個統一的架構,方便於使用上的資訊分享。基本上數位典藏是採用中央研究院資訊科學研究所文獻處理實驗室的技術來擴展,將其應用在更廣的層面,茲分別簡介如下:
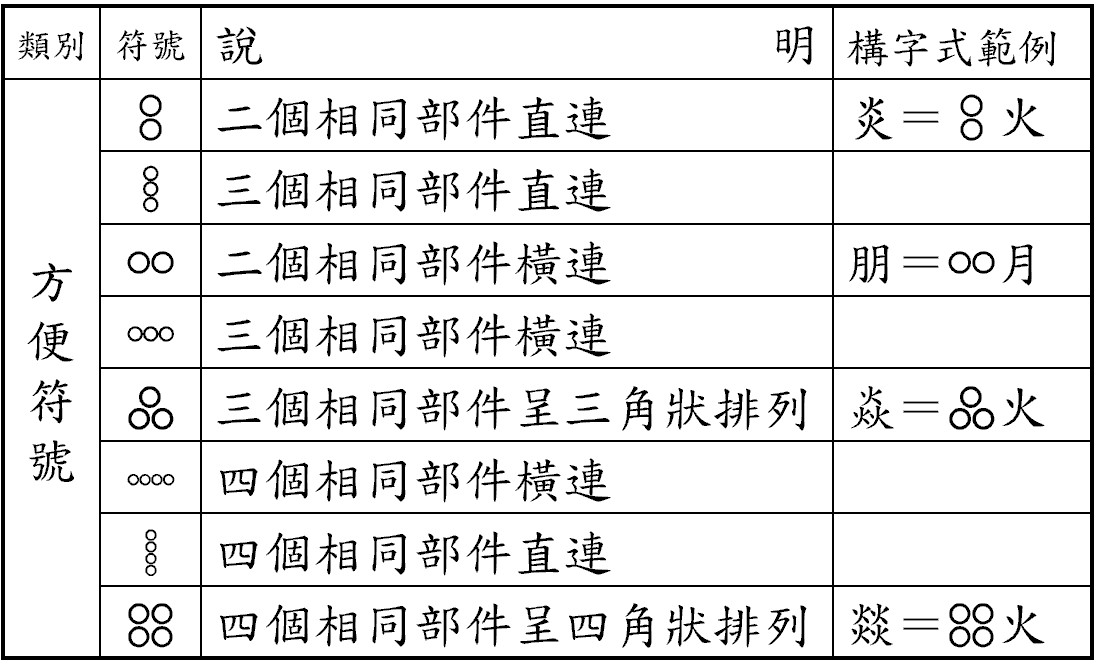
● 構字式
為了徹底解決現行漢字交換碼不足所造成的缺字問題,中研院資訊所文獻處理實驗室從漢字字形結構的拆分與分析中,利用有限的部件及字根的組合方式來表達任一漢字,此稱為構字式。例如『顥』,以構字式拆解的話,可拆分成『景』與『頁』兩個部件,其中為了表示部件與部件的連接關係,
故定義了三類共計十三個的『構字符號』,故『顥』的構字式為『 』。因此構字式是由部件和構字符號組成,且『構字符號』也是一般文字和缺字的辨識依據。
構字符號種類如表一、表二所示。利用簡單的連接符號為主來架構出中文字體,部分較複雜之字形則以起始符號、終止符號包夾來表示。
表一
表二
● 漢字構形資料庫
利用構字式的方法,將所有的漢字收錄並集結成一個以Big5為編碼的系統,稱為『漢字構形資料庫』。目前漢字構形資料庫已收錄了楷體字形62,242個、小篆11,100個、金文3,781個,異體字12,809組,所以當各典藏單位面對數位化所遭遇到的缺字問題時,若使用漢字構形資料庫做為缺字的解決方案未嘗不是個成本較低、功能又較完備的好方法。且目前漢字構形資料庫仍然持續在資料量上擴充。
目前漢字構形資料庫是由甲骨文、金文、楚系文字、小篆及楷書構形資料庫組合而成,如圖一。從圖一可看到每個構形資料庫都有各自的字集、部件集、字根集、異體字表及電腦字型,各個字集間彼此也有銜接。簡單的說,漢字構形資料庫的主要特色如下:
1. 銜接古今文字以反映字形源流演變。
2. 收錄不同歷史時期的異體字表,以表達不同漢字在各個歷史層面的使用關係。
3. 記錄不同歷史時期的漢字結構,以呈現漢字因義構形的特點。
4. 使用構字式及風格碼來解決古今漢字的編碼問題。
圖一
更多關於漢字構形資料庫的資訊可參考http://www.sinica.edu.tw/~cdp/。
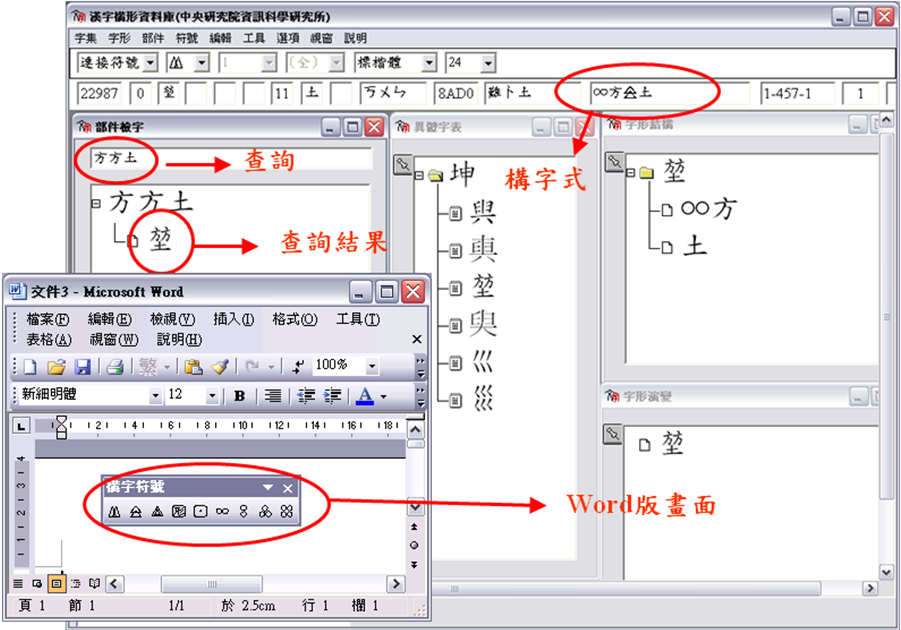
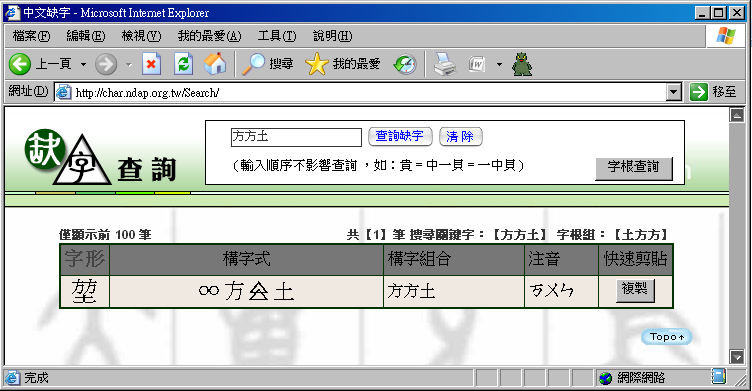
● 網頁缺字應用
目前資訊科技與網際網路的快速發展,人們更常利用網際網路取得資訊內容,而且使用網際網路來推廣數位典藏的內容也是強而有效的方式之一,在利用網際網路推廣之前,則必須先解決缺字顯示於網頁上的問題。網頁顯示部份,須將資料中包含構字式內容轉換成圖片格式的缺字字形,當使用者開啟了含有缺字之網頁時,會啟動網頁中所包含的JavaScript程式對資料內容進行判斷,並將構字式轉換成HTML的圖片標籤(IMG TAG);而圖片的網址(URL)將連結到字形解譯引擎(Glyph Rendering Engine),同時傳入該字形相關參數,如字元編碼、大小及顏色等。最後在使用者端觀看到的網頁,即是以圖片顯示出的缺字資料,如下圖二。另外,也提供缺字檢索網頁,如下圖三,供一般使用者即使尚未安裝漢字構形資料庫也能夠查詢缺字,其功能包含了圖片複製、構字式複製、調整字形顏色、大小。
圖二 網頁缺字顯示畫面
圖三 缺字檢索頁面 目前仍存在的缺字問題是古漢字的造字量、使用上的便利性以及各政府機關彼此系統的整合。古漢字的造字方面目前仍由中研院資訊所文獻處理實驗室持續進行中;然而漢字構形資料庫由於描邊字型的檔案太大,整個資料庫的下載壓縮檔約為80MB,再加上下載後的安裝問題,也會讓部分使用者卻步。其實對大多數人而言,缺字出現的機會並不多,於是在未來打算同時推出缺字圖片下載,方便大眾使用;在政府機關以及各機構所用的缺字解決方案不一,政府機關(如戶政、地政等機關)大多數使用全字庫(http://www.cns11643.gov.tw/),而數位典藏應用上則是以漢字構形資料庫為主,雖然彼此的解決方法各有其優缺點,且都已經在各單位實施一段時間,但是這之間的缺字資訊交流則是重要的一大課題,若不能及早整合資訊,也許在未來統整上會更加困難。
(全文完)
|