



























書同文,編碼大不同
Tags: none 發表: 2007-12-06, 點閱: 7,625 , 加入收藏櫃 , 列印
,
列印
,  轉寄
轉寄
想加入的書籤:














何謂編碼?
有哪些種類的編碼方式?
由於電腦並不像人腦,可以理解人的語言或文字,因此為了讓電腦接受到使用者輸入的訊息,所有的資料都會被轉換成0與1的數字後才進行處理,故有人說電腦是由0與1所組成的,而資料都會被轉換成0與1的過程,也就是所謂的編碼。在許多情況下,電腦編碼方式所能容納的字數是有限的,所以沒辦法涵蓋完整想要表示的字,例如:廣泛被使用的Big5編碼只是包含中文的常用字及符號而已,故以Big5編碼為主的電腦,僅能處理中文字所有集合(字集)中的一小部份。當然也有一個編碼包含許多字集的,例如Unicode的目標是包含所有字集。
英文系統內一樣有編碼。以一字節八位元(8 bits)排列,共可得256個組合,即0至255。但由於英文字母加上大小寫及常用的符號後,也不到128個,所以在早期的電腦系統內,只用了0至127(即十六進制的00至7F)。西文由於基本字符少,所以用2的8次冪就能包涵所有的字元。它的內碼集共0至255,名為ASCII。
現行的系統下,在同一種環境中,只能顯示一種編碼,所以只要這個編碼沒支援的字,就沒辦法顯示。目前常見之中文編碼有Big5(臺灣)、GB 2312(中國大陸)、國際標準Unicode等等,茲分別簡介如下:
- Big5:編碼是使用繁體中文社群中最常用的電腦漢字字符集標準,共收錄13,053個漢字,其中有2字為重複編碼。是在1984年由中華民國財團法人資訊工業策進會為五大中文套裝軟體所設計的中文內碼,所以就稱為Big5中文內碼,雖然五大套裝軟體並沒有成功,但Big5編碼卻深遠地影響正體中文電腦內碼,直至今日。Big5後來被人按英文字序譯回中文,以致現在有『五大碼』和『大五碼』兩個中文名稱。
- GB 2312:是一個簡體中文字符集的中國國家標準,全稱為《信息交換用漢字編碼字符集·基本集》,又稱為GB0,由中國國家標準總局發佈,1981年5月1日實施。GB 2312編碼通行於中國大陸,新加坡等地也採用此編碼,中國大陸幾乎所有的中文系統和國際化的軟體都支持GB 2312。GB 2312標準共收錄6,763個漢字,但是對於人名、古漢語等方面出現的罕用字,GB 2312不能處理,這導致了後來GBK及GB 18030漢字字符集的出現。
- Unicode:是一種在電腦上使用的字元編碼。它為每種語言中的每個字元設定了統一且唯一的二進位編碼,以滿足跨語言、跨平台進行文本轉換、處理的要求。隨著電腦工作能力的增強,Unicode也在面世以來的十多年裡得到普及。由於Unicode在其編碼中同時容納了全世界各種語言的字元和符號,因此已成為國際常用的交換碼標準。目前Unicode在漢字的支援方面已經定義超過七萬多個字元,收納的字遠多於Big5,且收納字的範圍還在繼續增補中,因此也的確解決了某些層次字形編碼不足的問題,並且在許多系統的支持下,在資訊交換上也的確有其便利性。

中文字編碼存在哪些問題?
電腦的編碼系統原本是採用一個字對一個碼,才能夠在電腦上顯示出來,人類雖然看得懂字形,但是電腦只能看懂編碼,且能夠被放到電腦的數量,受限於編碼空間的限制,必須挑選適當的文字或符號放到電腦,再將這些文字或符號加以編碼。其他沒有被收錄的文字,如果使用者需要在電腦上使用,將無法順利於電腦上表達出來,這些文字則稱為缺字。
由於數位典藏機構需要將大量的古代文獻數位化儲存,而古籍中又包含了大量的罕用文字,故經常發生缺字問題,所以缺字問題也成為漢字數位化過程中最急迫的問題之一。為了解決缺字問題,最常用的方法是利用使用者造字區內自行新增所需之缺字,但此方法在面對資料檢索或是交換時,因另一方可能沒有相同的造字檔,而遭遇資料錯誤、無法讀取或文字空白等問題,故並未徹底解決缺字問題,再加上當使用者造的字越來越多時,複雜的管理問題也隨之而來。
我們以『游錫堃』、『王建煊』這兩個姓名來舉例,『堃』、『煊』這兩個字在Big5編碼中是不存在的,而在Unicode編碼中是存在的。所以當我們所編輯的文件格式預設編碼為Big5時,這些未存在於Big5編碼中的文字會以問號顯示;而在HTML網頁原始碼的文件上,則會以該字的跳脫字元格式(Escapes)來表示,例如:『堃』會表示為『堃』、『煊』會表示為『煊』。若需要正確顯示這些文字,只需要將文件的編碼格式設定為包含該文字的編碼格式,例如:Unicode。
數位典藏機構所提供的解決方案?
數位典藏的古籍資料中有相當數量的缺字存在,所以在缺字的解決上必須有一個統一的架構,方便於使用上的資訊分享。基本上數位典藏是採用中央研究院資訊科學研究所文獻處理實驗室的技術來擴展,將其應用在更廣的層面,茲分別簡介如下:
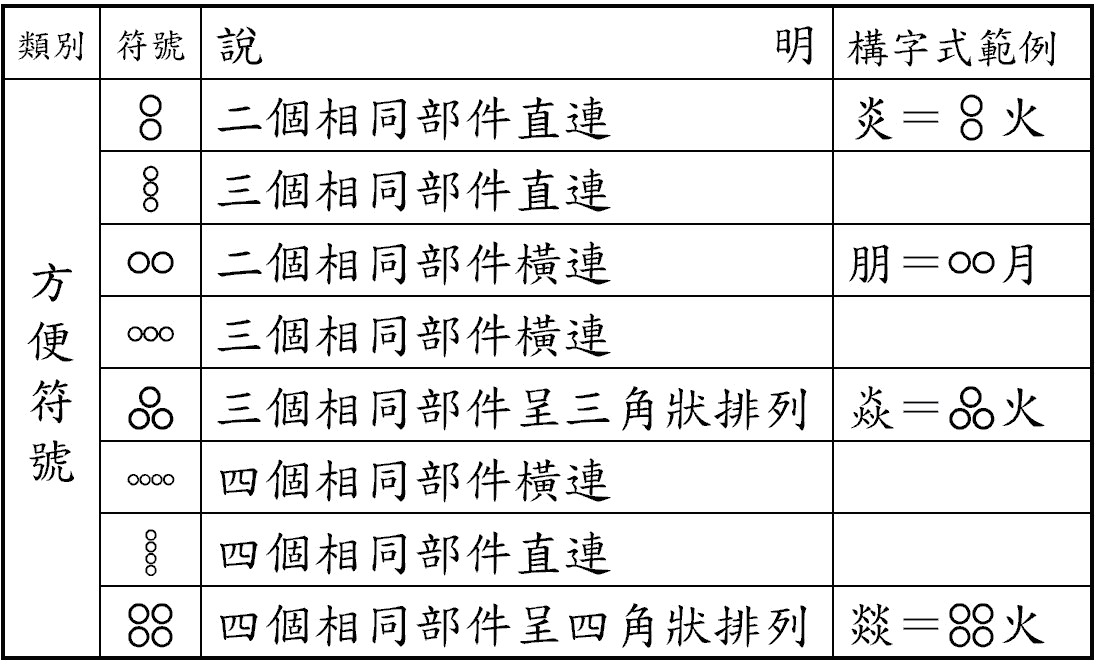
- 構字式:為了徹底解決現行漢字交換碼不足所造成的缺字問題,中研院資訊所文獻處理實驗室從漢字字形結構的拆分與分析中,利用有限的部件及字根的組合方式來表達任一漢字,此稱為構字式。例如『顥』,以構字式拆解的話,可拆分成『景』與『頁』兩個部件,其中為了表示部件與部件的連接關係,故定義了三類共計十三個的『構字符號』,故『顥』的構字式為『 』。因此構字式是由部件和構字符號組成,且『構字符號』也是一般文字和缺字的辨識依據。構字符號種類如表一、表二所示。利用簡單的連接符號為主來架構出中文字體,部分較複雜之字形則以起始符號、終止符號包夾來表示。
- 漢字構形資料庫:利用構字式的方法,將所有的漢字收錄並集結成一個以Big5為編碼的系統,稱為『漢字構形資料庫』。目前漢字構形資料庫已收錄了楷體字形62,242個、小篆11,100個、金文3,781個,異體字12,809組,所以當各典藏單位面對數位化所遭遇到的缺字問題時,若使用漢字構形資料庫做為缺字的解決方案未嘗不是個成本較低、功能又較完備的好方法。且目前漢字構形資料庫仍然持續在資料量上擴充。
目前漢字構形資料庫是由甲骨文、金文、楚系文字、小篆及楷書構形資料庫組合而成,如圖一。從圖一可看到每個構形資料庫都有各自的字集、部件集、字根集、異體字表及電腦字型,各個字集間彼此也有銜接。簡單的說,漢字構形資料庫的主要特色如下:
1. 銜接古今文字以反映字形源流演變。
2. 收錄不同歷史時期的異體字表,以表達不同漢字在各個歷史層面的使用關係。
3. 記錄不同歷史時期的漢字結構,以呈現漢字因義構形的特點。
4. 使用構字式及風格碼來解決古今漢字的編碼問題。
評分:
 (No Ratings Yet)
(No Ratings Yet)
