



























檔案比對--數位資料庫的鍊金術
Tags: none 發表: 2008-07-11, 點閱: 4,049 , 加入收藏櫃 , 列印
,
列印
,  轉寄
轉寄
想加入的書籤:














檔案比對--數位資料庫的鍊金術
吳寶原、周海文
中華電子佛典協會
service@cbeta.org
摘要
從傳統紙本書庫到現代數位資料庫,因應承載媒體的轉換,作業觀念及方法也必須就數位特性而有所變通。本文敘述檔案比對技術協同相關工具程式,對於數位資料庫生產、維護、修訂、更新上的應用發展,以及檢查各類成果的正確性,提出一道生生不息、永續經營的秘方。
關鍵詞:CBETA、電子佛典、檔案比對、比對差異、差異頻次。
1. 前言
筆者任職於中華電子佛典協會(以下簡稱CBETA)。1998年CBETA開始進行佛典數位化作業,2007年完成《大正藏》、《卍續藏》兩大藏經中不重複的漢傳佛教典籍,內容總字數超過一億五千萬字,且校對品質之精良深得學界肯定。
良好的數位資料庫至少要滿足三個條件:一是量要夠,二是質要精,三是檢索方便。前兩者是資料庫建構的基礎工程,數量關係到輸入,品質牽涉到校對。只有把這兩項基礎工程確實做好,資料庫的檢索才能顯出信度及效度的應用價值。
檔案比對是指對「同一份資料」兩個或兩個以上之電子檔的相互比對。網路上流傳的佛經電子檔,同一經文常有重複輸入的情形,我們在多方搜集後比對利用,以得到一個更好的電子版本,如此即可省卻重新輸入及多次人工校對的程序。這是CBETA在檔案比對技術上最原始的應用方式,之後在不斷的經驗累積下,檔案比對的觀念及方法逐漸廣泛運用在更多的作業環節。
2. 原理概述
對於藏經資料的輸入與校對,就筆者所知,很多佛教單位都只做一次輸入,然後就拿這一份輸入檔進行不斷反複的校對訂正程序。
假設這一份檔案有一萬字,再假設它剛完成輸入時其實有一千個錯字,那麼也就是說它其實有九千個字根本沒問題。可是,這一萬字,不管它客觀上的對錯如何,對於每一校的校對人員來說,他都要瞪大眼睛一個一個去校讀。因此,我們把思考跳開來看,是不是所有的校對人員都浪費了九成的力氣在找錯字呢?
如果有一種可靠的方法,可以讓校對者區分「有問題的一千字」與「沒問題的九千字」,那麼只要針對「有問題的一千字」來下功夫,豈不是很妙--這就是「檔案比對」的妙用。
2.1 程式界面
許多軟體都有提供檔案比對功能,但CBETA為自己量身訂做了一個功能超強的檔案比對程式。程式界面如下(圖1):
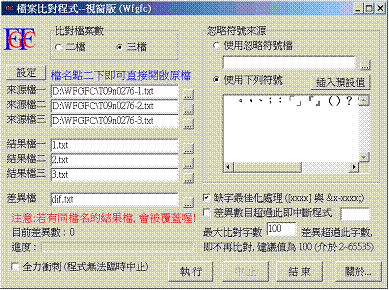
圖1 檔案比對程式界面
◎本程式下載位址:http://www.cbeta.org/download/wfgfc_v13.zip
◎本程式操作說明請參考下載檔案中之 readme.txt
◎本程式詳細設計原理可參閱:http://www.cbeta.org/data/cbeta/fgfc.htm
2.2 比對實例
假設一次比對三份不同編排格式的經文,比對時忽略半形空格、全形空格及標點符號,如上面程式界面的設定,底下是簡要的實例:
【第一份經文 T09n0276-1.txt】
|
無量義經德行品第一 蕭齊天竺三藏曇摩伽陀耶舍譯 如是我聞。一時佛在王舍城耆闍崛山中。 與大比丘眾萬二千人俱。菩薩摩訶薩八萬 人。天龍夜叉乾闥婆阿修羅迦樓羅緊那羅 摩[目*侯]羅伽諸比丘比丘尼優婆塞優婆夷俱。 大轉輪王小轉輪王。金輪銀輪諸轉輪王。國 王王子國臣國民。國士國女國大長 |
【第二份經文 T09n0276-2.txt】
|
無量義經德性品第一 蕭齊 天竺 三藏 曇摩伽陀耶舍 譯
如是我聞。一時佛在王舍城耆闍窟山中,與大比丘眾萬二千人俱; 菩薩摩訶薩八萬人;天、龍、夜叉、乾闥婆、阿修羅、迦樓羅、緊那羅 、摩侯羅伽、諸比丘、比丘尼、優婆塞、優婆夷俱、大輪王、小輪王、 金輪、銀輪諸轉輪王、國王、王子、國臣、國民、國士、國女、國大長 |
【第三份經文 T09n0276-3.txt】
|
無量義經德行品第一 蕭齊天竺三藏曇摩伽陀耶舍 譯 如是我聞一時佛在王舍城耆闍崛 山中與大比丘眾萬二千人俱菩薩 摩訶薩八萬人天龍依叉乾闥婆阿 修羅迦樓羅緊那羅摩&K3-D4C6;羅伽諸比 丘比丘尼優婆塞優婆夷俱大轉輪 王小轉輪王金輪銀輪諸轉輪王國 王王子國臣國民國士國女國大長
|
【比對之後的第一個結果檔 1.txt,共有六處差異字串】
|
無量義經德{{行||性||行}}品第一
蕭齊天竺三藏曇摩伽陀耶舍譯 如是我聞。一時佛在王舍城耆闍{{崛||窟||崛}}山中。 與大比丘眾萬二千人俱。菩薩摩訶薩八萬 人。天龍{{夜||夜||依}}叉乾闥婆阿修羅迦樓羅緊那羅 摩{{[目*侯]||侯||&K3-D4C6;}}羅伽諸比丘比丘尼優婆塞優婆夷俱。 大{{轉輪王小轉||輪王、小||轉輪}}{{||||王小轉}}輪王。金輪銀輪諸轉輪王。國 王王子國臣國民。國士國女國大長 |
3. 相關工具程式
檔案比對程式必須協同其它相關工具程式才能在實務應用上達成各種工作需求。底下介紹的這些工具程式也都由CBETA自行研發,有興趣試用者可與筆者連絡。
3.1 格式化
古籍數位化很重要的一點是對資料出處予以定位,而且定位描述得越詳細越好。比如某筆資料是來自哪套藏經、哪個編號、哪一冊、哪一頁、哪一欄、哪一行。CBETA數位化電子佛典的每一行都有定位資訊,我們稱之為「行首資訊」;而產生「行首資訊」的過程,我們稱之為「格式化」。
格式化是依據輸入資料所標記的「頁、欄」由程式自動產生。輸入資料的「頁、欄」標記如下:
| p0195c
佛說佛名經卷第三
南無大海佛 南無大樂說佛 南無大藥王 佛 南無大功德佛 南無無量香佛 南無 |
格式化程式界面如下(圖2):

圖2 格式化程式界面
執行之後稍加整理,得到以下結果:
|
T14n0441_p0195c01║ T14n0441_p0195c02║佛說佛名經卷第三 T14n0441_p0195c03║ T14n0441_p0195c04║南無大海佛 南無大樂說佛 南無大藥王 T14n0441_p0195c05║佛 南無大功德佛 南無無量香佛 南無 |
3.2 看圖校對
本程式是解決比對差異的絕佳利器。藉由「行首資訊」,程式可以開啟與差異檔相對應的原書圖檔,並自動定位在差異所在位置,且提供用字選擇。如下(圖3):
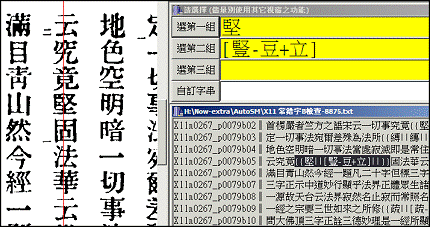
圖3 看圖校對程式界面
3.3 差異頻次統計
檔案比對之後的差異檔,當中的差異字串是處理重點。因此對差異字串予以分類統計,一來可以瞭解比對檔的狀況,二來方便決定接下來的處理方式。
程式畫面如下(圖4):

圖4 看圖校對程式界面
統計結果的格式如下:
|
1 {{[口*宅]||詫||[口*宅]}} …… 76 {{是||是||}} 85 {{妒||妒||[女*石]}} 99 {{&M-023540;||[束*力]||敕}} 227 {{祇||祇||祗}} 總共有10,311個。 |
3.4 批次字串取代
使用上述「差異頻次統計」程式所產生的統計結果,屬於「高頻」或「有規則」的差異字串經常可以取代為某一固定字串。比如舊式圈點經文跟新式標點經文比對之後,可以製作成類似這樣的取代表:
| {{。||:「}}=:「
{{。||,}}=, {{||。}}=。 |
然後交給這支程式來進行批次取代,以便將標點方面的差異迅速處理掉。程式界面如下(圖5):
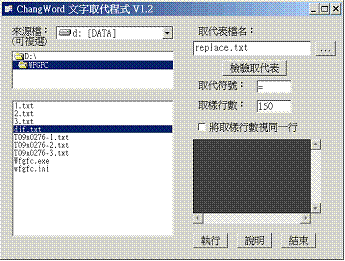
圖5 批次取代程式界面
3.5 分割差異檔
當比對差異檔處理到某種程度,比如說有關新式標點方面的差異全部處理完畢,這時候利用這支程式按差異字串狀況把差異檔一分為二(或一分為三,端視差異檔由幾個檔案比對而成),即可得到含有新式標點的經文檔。
程式界面如下(圖6):
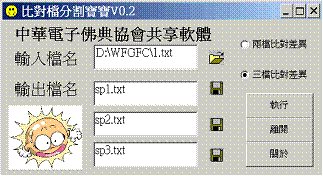
圖6 分割差異檔程式界面
4. 實務應用之一──普遍應用
「檔案比對」不只是一支程式,更重要的,它是一個作業觀念及方法。妥善的應用它,對於數位資料庫的各個層面都可以有高效率的表現。
4.1 生產:建立資料的可靠性
如前所述,透過檔案比對及相關程式的運用,不只大量節省校對成本,而且可以得到極為接近書面內容的數位化資料。CBETA電子佛典發行已經九年,這九年來讀者回饋經文勘誤報告中屬於CBETA作業疏失者極為少見。
4.2 維護:維護資料的穩定度
資料庫建立之後,儲存媒體的損毀,人為修訂的疏忽,都可能造成難以挽救的局面。因此,CBETA經文資料庫一直保持兩個文字內容一致的版本(「簡單標記版」及「XML版」),並由不同人在不同電腦上負責維護。每一次的經文修訂,都由不同人對不同版本予以修訂,然後每年至少執行一次版本大比對,若出現差異則予以訂正,如此使資料庫內容文字維持在最穩定的狀態。
4.3 修訂:提昇資料的正確度
CBETA電子佛典的底本之一是《大正藏》,而《大正藏》的主要底本則是《高麗藏》。我們在2003年完成《大正藏》作業後,韓國高麗大藏經研究所2004年發表了《高麗藏》電子檔。因此我們以CBETA完成的《大正藏》電子檔比對《高麗藏》同一經目的電子檔,從兩者的差異,的確發現了不少《大正藏》的錯誤。因此,CBETA電子佛典的數位資料正確度得以往上不斷提昇,甚至可以超越《大正藏》紙本上的資料內容。
4.4 更新:增進資料的豐富性
「佛典新標(新式標點)」是我們近年正在執行的作業。許多佛教單位或個人對一些著名的經論或多或少都有進行過經文電子檔的新標作業,但其電子檔的排版格式及用字標準不同於CBETA,所以我們在取得授權後,就以檔案比對的方式,把新標電子檔裡面的新式標點符號通通「套入」到我們維護的檔案中。利用這個比對後的套入手法,CBETA電子佛典將會逐漸去掉「沒標點」或「只有圈點」的舊衣,而一步步換上「新式標點」的新裝。
4.5 其它:雙人同工、作業前後
許多作業上重要的處理步驟,如看圖校對作業,可以採用「雙人同工」──讓兩個人執行一樣的工作,然後再比對兩者的作業結果。又,個人在執行重要作業步驟的過程中,也可以分幾個階段步步前進,每一步的結果都跟前一步比對,查看是否有異常差異,然後才再進行下一步。再者,也可以以經過最後訂正的完成檔,比對當初作業人員交回的結果檔,從其差異狀況可以了解作業者的盲點,而從其差異數量可以做為作業成效考核的依據。
5. 實務應用之二──成果檢查
CBETA作業成果展現在各種不同版本格式的經文檔。其實CBETA各版經文主要是由XML版透過程式所產生的,若程式有一點點小錯誤,就可能造成無法預期的錯誤結果。為避免發生錯誤,從程式來除錯是一件非常困難的事,尤其是在原始資料增加新格式或XML有新標記時,程式要全面考量到是不太容易的,但藉由「檔案比對」概念所發展的方法卻可以輕易達到成果檢查的目的。底下就針對CBETA各版經文的檢查流程來探討檔案比對可以做哪些事。
5.1 普及版比對
普及版是CBETA經文最基礎的版本格式。本版格式是一卷一檔,每一行皆有原書的行首資訊,斷行位置依原書格式,經文中只要是非BIG5字集的文字會優先採用意義相同的通用字,若無通用字則使用組字式,若CBETA對經文有所修訂則採用修訂後的文字,而校勘方面的標號及文字皆不呈現。
普及版經文的比對方式:
1. 利用程式由XML版產生標準的普及版格式經文。
2. 利用程式由簡單標記版也產生一套普及版格式經文。
3. 二份普及版經文進行比對。
在正常情況下,二份經文應該完全一致,如此即可視為產生的經文為正確的結果。若比對有差異,則檢查經文與程式,直至差異完全消失為止。
經過上面的流程,我們就有了一份標準的普及版經文,而這一版本也是後續比對的重要依據。
5.2 APP版比對
APP版的格式和普及版類似,差別處在於經文格式不依原書格式斷行,而是在標點符號處或特殊格式處斷行。如此斷行的主要目的是讓一般文字檢索程式可以正確搜尋經文用字,而不會因為斷行造成無法搜尋。本版的比對方式如下:
1. XML版產生APP版格式經文,例如:
T08n0221_p0001a08(00)║聞如是。一時佛在羅閱祇耆闍崛山中。
T08n0221_p0001a09(02)║與大比丘眾五千人俱。皆是阿羅漢。
2. 簡單標記版產生普及版格式經文,例如:
T08n0221_p0001a08║聞如是。一時佛在羅閱祇耆闍崛山中。與大
T08n0221_p0001a09║比丘眾五千人俱。皆是阿羅漢。
3. 利用程式將上述二版的行首去除,同時也去除換行符號,意即將每一行都接起來,理論上二者皆轉成如下:
聞如是。一時佛在羅閱祇耆闍崛山中。與大比丘眾五千人俱。皆是阿羅漢。
4. 比對二份處理後的結果,若沒有差別,表示文字正確度無誤。
這個比對方式雖然無法確保APP版格式完全正確,但至少在經文用字的品質上是正確的,而格式上可以由抽樣來檢查看看是否有問題。
5.3 UTF8版比對
UTF8版的特色是若經文缺字是屬於UTF8字集的範圍,則優先轉換成UTF8字集的用字,其次才是轉換成通用字,最後才是保留組字式。本版的比對方式如下:
1. XML版產生UTF8版格式的經文。
2. 簡單標記版產生普及版經文,但缺字一律使用組字式,此版暫時名為「組字式版」。
3. 利用程式將「組字式版」的缺字依缺字資料庫取代為通用字及組字式。
4. 將此版與普及版比對,若結果相同,表示「組字式版」是正確的格式。
5. 再利用程式將「組字式版」的缺字依缺字資料庫取代為UTF8字集及組字式。
6. 將此版與UTF8版比對,若二者相同,即表示UTF8版的內容正確無誤。
7.
5.4 PDF版比對
CBETA的PDF版是利用Java程式搭配PDF相關函式庫產生。本版的比對方式如下:
1. 利用PDF相關工具程式將CBETA的PDF版經文轉成純文字格式,此時轉換出來的是UTF8格式。
2. 利用程式將上述版本轉換成BIG5格式,並同時把非BIG5的文字轉換成組字式。
3. 利用程式將CBETA的UTF8版換成BIG5版,並同時把非BIG5的文字轉換成組字式。(此步驟不能用普及版來做,因為普及版有許多缺字已轉換成通用字)
4. 將步驟二與步驟三的結果使用CBETA「檔案比對程式」來比對,因為此二格式差異較大,不易由一般的比對程式來處理。在比對時要忽略「0123456789_」等阿拉伯數字及全、半型空格等符號,若比對無誤即表示PDF版經文的文字正確度無誤。
這個比對也是將重點放在經文文字的正確度,至於PDF的格式只能藉由抽樣檢查與使用者的回報來予以修改。
5.5 CBETA光碟上經文的品質檢查
CBETA光碟主要的經文內容是由CBReader閱藏系統搭配XML經文所產生。此XML經文即為CBETA原始的XML經文,唯一的差別在於切成一卷一檔,以利程式在分析時提升處理速度。執行檢查時的比對方式如下:
1. 設定CBReader輸出的格式。因為CBReader有各種格式的設定,無法做到每一種都檢查,所以會以最常用的格式搭配可比對的現有經文格式來檢查。
2. 啟動CBReader除錯模式,此模式可以將每一卷所呈現的經文皆自動另外存成獨立的html檔。
3. 利用程式將html的標記去除。
4. 利用「檔案比對程式」將上一步驟與普及版的經文比對,比對時要忽略少許特殊格式。
5. 若比對無誤,即表示CBReader所產生的結果正確度無誤。
6. 結語
資料庫可以是「死」的,也可以是「活」的;死的資料庫當裝滿了資料就告終結,而活的資料庫在用心照顧下得以不斷成長。建構一個重要的數位資料庫必須要有永續經營的理念及作為──這是我們對「CBETA電子佛典集成」資料庫的許諾。我們在此以CBETA的經驗所介紹的「檔案比對」技術,的確可以讓資料庫內容在穩定中越來越正確、越豐富,正所謂「生生不息」也,因此稱之為「數位資料庫的鍊金術」。
至於本文敘述的這一套「檔案比對」技術是否可以應用在其它資料庫?若是文字資料庫,我們所開發的程式或許可以派上用場,比如「檔案比對程式」,但它只支援BIG5純文字,尚未支援Unicode字集及其它非純文字的文件。若是文字類型以外的資料庫,則可能要按資料庫的內容特性去開發新程式,或者尋找適合的比對工具及相關軟體。目前許多檔案管理軟體(如Windows Commander)、文書處理軟體(如UltraEdit)都附有「檔案比對」功能,只要好好運用,不但可以對不同資料夾內的組成文件做同步比對,也可以對不同檔案的位元組成內容、存檔日期等等異動情況得到比對差異。因此,只能說「經驗與概念重於工具,而工具是很容易打造的」――這是我們程式設計師給這個問題的答覆。
參考文獻
[1] 吳寶原,1998,《從實務經驗談電子佛典初步工程之演進》,佛教圖書館館訊 第十四期。
http://www.gaya.org.tw/journal/m14/14-index.htm
[2] 周海文,1999,《檔案比對程式在佛典電子化上之應用》。
http://www.cbeta.org/data/cbeta/fgfc.htm
[3] 吳寶原,2000,《創意靈感--關於電子藏經的輸入、校對及編輯》,佛教圖書館館訊 第二十四期。
http://www.gaya.org.tw/journal/m24/24-index.htm
[4] CBETA,2006,《中華電子佛典協會暨中華佛學研究所-佛典數位典藏計畫數位化工作流程簡介》。
http://content.teldap.tw/main/doc_detail.php?doc_id=658&class_vision=18
[5] CBETA相關技術,http://www.cbeta.org/tech
[6] CBETA版本格式,http://www.cbeta.org/format
[7] CBETA經文凡例,http://www.cbeta.org/data-format
評分:
 (No Ratings Yet)
(No Ratings Yet)
